Day 21: 84 Articles. 225 Views. 0 Likes. So I Had AI Build Me a Growth System.
I had 84 published articles and 225 monthly views. I spent a day using AI to build a growth system
I had 84 published articles and 225 monthly views. I spent a day using AI to build a growth system
One prompt framework for four AI video models. Learn the 8-layer template, then adapt it to the unique controls of Runway Gen-4.5, Kling 3.0, Veo 3.1, and Seedance 2.0.
A practitioner''s image to video AI prompt guide covering the 5-element template framework, model-specific strategies for Runway Gen-4.5, Kling 3.0, Veo 3.1, and Sora 2.0, plus scene-by-scene prompt templates and common pitfalls.
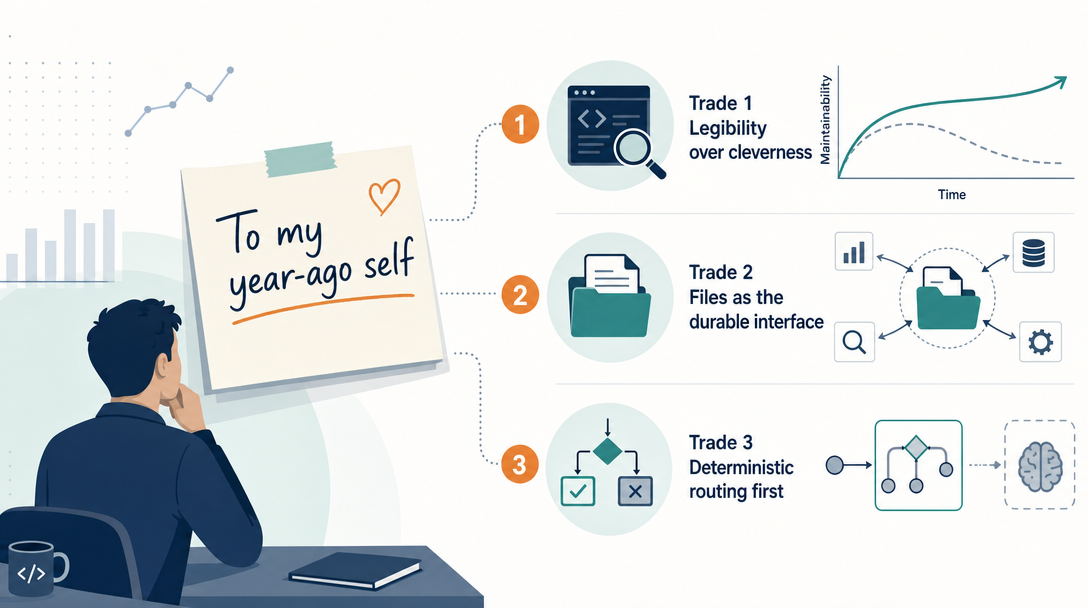
Twelve design decisions explain why OpenClaw looks the way it does — and what each one cost. Single process. Files as truth. Deterministic routing. Each one trades clever for legible. The trade is the point.
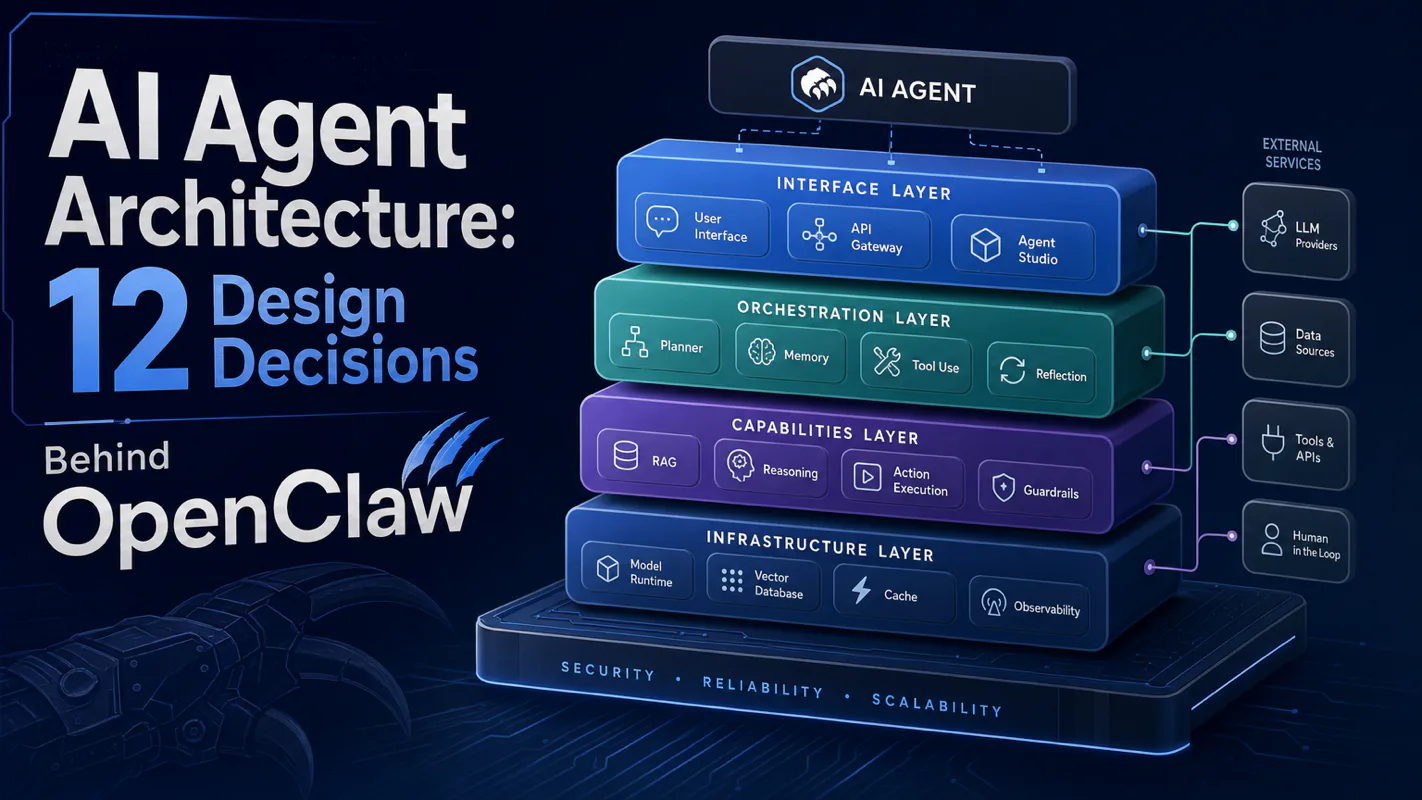

TL;DR: AI agent architecture is a pile of tradeoffs. OpenClaw's twelve key decisions all trade clever for legible. Single process beats microservices for one-operator scale. Files-as-truth beat databases for portability. Deterministic routing beats AI routing for debuggability. Three-tier memory beats one big file for sustainability. Each decision has a cost, and each cost is paid willingly because the alternative trades observability for performance.
Everyone says architecture decisions are "you gotta know all the patterns." Actually, the OpenClaw decisions came from refusing complexity until it was forced. Twelve calls, ten of them in the direction of less, made the runtime portable, debuggable, and writable.
If you already shipped a runtime of your own, skip ahead to the closing decisions. If you are still picking your stack, read on through the twelve calls.
You've now seen nine articles on the parts: runtime, message flow, agent loop, memory, context, workspace, multi-agent, sessions, security. This last one zooms out and asks: why does the whole thing look this way?
Honestly? Try this question: if you were building OpenClaw today, would you make the same calls?
The answer for most decisions is yes. Some I'd revisit. A few were made under constraints that no longer apply. The exercise of walking each decision and asking "would I make this again?" is what separates an architecture you've absorbed from one you've merely read about.
The rest of this article walks the twelve decisions, explains what each one cost, what it bought, and which ones I'd reconsider. By the end, you'll have a mental model for not just OpenClaw but for any AI agent architecture decision you face going forward.
If you've followed the series, two short maps to keep open:
Here is why this matters: the wrong call early in a runtime compounds for years. Single process versus microservices, files versus database, deterministic versus AI routing. Each was reversible only at heavy cost.
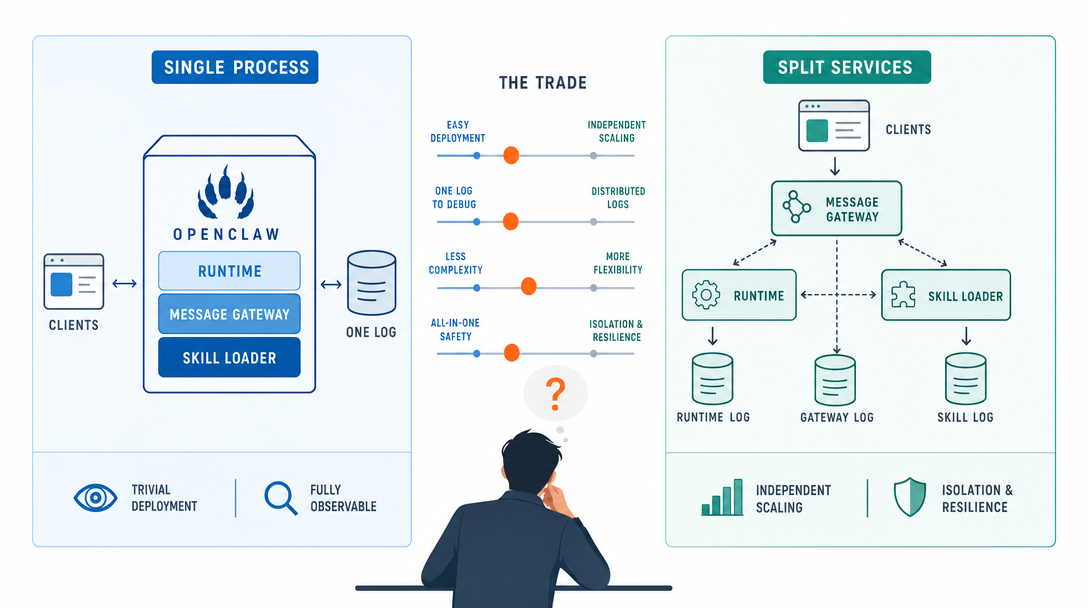
The choice: every agent runs in one OS process.
The cost: a bad plugin can take down everything.
What it bought: <100ms cold start. ~120MB per agent vs. ~600MB. Five agents on a 16GB Mac Mini comfortably. One command to start; one command to stop.
Would I reconsider? No. At the scale most operators run (1-10 agents on one machine), microservices' isolation benefit is dwarfed by their coordination cost. The crash isolation argument is real but rare, in three months I've had the gateway restart from a bad plugin once. Eight seconds of downtime versus three docker-composes' worth of complexity is not a contest.
Before files-as-truth, agent state lived in opaque databases and required tooling. After, every fact is in a Markdown file an editor can open. Backups are git, edits are diffs, audit is grep. Boring, durable, and yours.
The choice: identity, memory, configuration all live as Markdown files on disk.
The cost: queries are slower than a database. Past a few thousand entries, MEMORY.md gets unwieldy.
What it bought: portability (cp the folder, clone the agent). Git versioning. Editability with any text editor. Inspectability: you can read what the agent believes about itself. Trust: you can fix it when it's wrong.
Would I reconsider? Absolutely not. This is the load-bearing decision. Every other one flows from it. Files-as-truth is what makes the runtime operable for years rather than months.
The choice: a static rule table maps {channel, condition} → agent.
The cost: rigidity, a new channel needs a new rule.
What it bought: 100% reproducibility. Routing failures are 5-minute config bugs, not 30-minute model behavior investigations. The audit log is meaningful.
Would I reconsider? No. AI routing was the experiment I tried and abandoned. The 90% accuracy of model-based routing is much worse than the 100% accuracy of a config table. Rule-based routing is boring; the boredom is the feature.
The choice: Layer 1 logs, Layer 2 MEMORY.md, Layer 3 SOUL.md, with explicit promotion rules.
The cost: requires understanding three different files instead of one.
What it bought: each layer can stay small enough to be operable. Promotion rules make "what gets remembered" explicit instead of accidental. SOUL.md never gets compacted, so identity is stable.
Would I reconsider? No, but I'd make memory promotion's UI better. The current "agent decides via memoryFlush" works but feels invisible. A tool to "show me what's about to be promoted, let me approve" would help.
The choice: all agents share one runtime process.
The cost: a misbehaving agent can affect siblings.
What it bought: cheap multi-agent setups. Five agents on one machine using 720MB of RAM total instead of 4GB.
Would I reconsider? Mostly no, but I'd add an opt-in "isolate this one agent in a separate process" flag for sensitive workloads. Some agents (e.g., agents handling financial data) are worth the IPC overhead for true isolation.
The choice: the agent loop has named stages, named termination conditions, and traceable per-round logs.
The cost: the loop is slightly less flexible than "anything goes."
What it bought: debuggability. When the agent loops too long or stops too early, you read the trace and find the exact stage. Traces over guesses.
Would I reconsider? No. I'd push it further, more granular sub-stages within stage 4 (tool execution) when tool calls are complex, so the trace shows tool argument validation separately from tool execution.
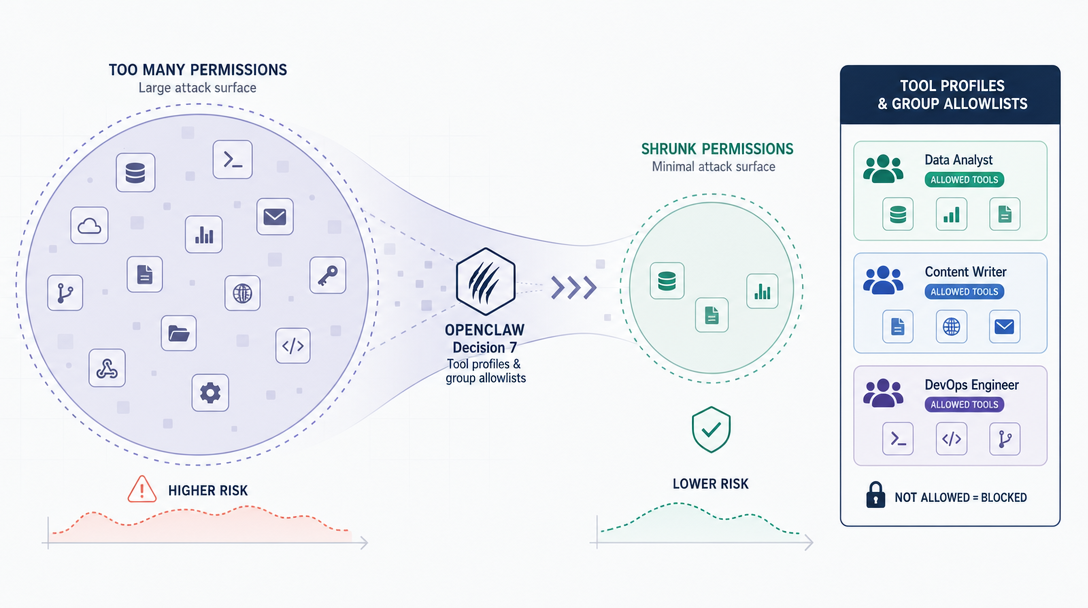
The choice: tools are bucketed behind profiles (minimal, coding, messaging, full) and group shorthands such as group:runtime, group:fs, group:sessions, group:memory, group:web, group:ui, group:automation, group:messaging, group:nodes, group:agents, group:media, and group:openclaw. Agents declare their effective allowlist, and the runtime enforces it.
The cost: more upfront config than "give every agent everything."
What it bought: blast radius is bounded by design. A messaging-only agent literally can't run shell commands, regardless of what an injection asks it to do.
Would I reconsider? No. I would make the profile/group distinction clearer earlier, because current OpenClaw already supports allow/deny policy beyond the broad profiles. Operators should start with a profile, then narrow with explicit allow/deny rules where needed.
The choice: 127.0.0.1 binding, not 0.0.0.0.
The cost: external integrations need a reverse proxy.
What it bought: no accidental public exposure. The default is safe.
Would I reconsider? No. The "secure by default" posture means new operators don't accidentally publish their gateway to the internet. The reverse-proxy requirement adds 10 minutes to setup but prevents serious incidents.
The choice: each agent run can take up to 10 minutes by default.
The cost: a runaway loop can chew through 10 minutes of API budget before being killed.
What it bought: real agent work, investigations, drafts, batch processing, has room to finish. A 60-second timeout would kill 70% of legitimate work.
Would I reconsider? No, but I'd add a soft warning at 5 minutes that surfaces in the trace, so long runs are visible before they terminate.
The choice: agents can emit explicit markers meaning "I did the work, but don't message the user." Current OpenClaw uses HEARTBEAT_OK for heartbeat acknowledgements and keeps NO_REPLY / no_reply for non-heartbeat silent work.
The cost: one more protocol detail to remember when writing skills, cron tasks, and background agents.
What it bought: heartbeat agents and background sync agents that don't spam you. The signal-to-noise ratio of running long-term agents.
Would I reconsider? No. Silent acknowledgement is one of those decisions that seems minor but compounds. Without it, multi-agent setups become noisy enough that operators turn them off. I would only teach the split earlier: HEARTBEAT_OK for heartbeats, NO_REPLY for other quiet tasks.
The choice: heartbeat cadence is configured through agents.defaults.heartbeat.every or per-agent settings. Current OpenClaw defaults to 30m, or 1h for Anthropic OAuth/token auth including Claude CLI reuse. Setting it to 0m disables heartbeat.
The cost: one config value operators must understand.
What it bought: a durable background pulse without confusing it with cron. Heartbeats keep agents alive and can run lightweight checks; cron handles explicit scheduled jobs.
Would I reconsider? No, but I would not describe the old 55-minute operator convention as the current default. It is a possible override, not the official baseline.
The choice: the runtime is written in TypeScript.
The cost: not as fast as Rust, not as integrated with Python's ML ecosystem.
What it bought: it runs the same on macOS, Linux, and basic servers without per-platform builds. The plugin ecosystem is huge. Hooks can be written in TypeScript or JavaScript directly.
Would I reconsider? This is the one I'd think hardest about. If I were starting today, Rust + Wasm plugins might be more future-proof. But the "single binary, runs everywhere, easy to extend" property TypeScript gives is hard to beat for the operator audience.
Of the twelve calls, eleven I would make again with full conviction. One I keep coming back to: making the gateway a single process with no built-in horizontal scale path.
The argument for: simplicity. One process means one config file, one log, one deploy unit. The blast radius of a bug is bounded. The agent feels like an appliance, not a fleet. For 95 percent of users, including me, this is the right call.
The argument against: the day someone needs ten agents on the same gateway, they hit a wall. Memory grows, the event loop gets crowded, embedded model calls start queueing. The mental model breaks because the assumption was personal runtime, not team runtime. Pricing the upgrade path means rewriting the gateway, which is the most stable part of the codebase.
If I were making the call again today, I would still pick single-process by default, but I would expose a documented seam earlier: a stable IPC protocol between gateway and agents, so a future power user can run agents on a separate machine without forking the runtime. That seam costs about 200 lines of code today and saves a fork later.
The lesson is not that single-process was wrong. It is that even the right call deserves an exit ramp documented from day one, especially when the simplicity it buys you also makes the upgrade scary.
A short list of changes I'd make to OpenClaw if I were starting fresh in 2026-04:
| Change | Why |
|---|---|
| Native MCP from day one | The protocol stabilized; integrating it as a first-class concept is cleaner than the current "MCP works but feels bolted on" |
| Memory promotion UI | The current memoryFlush + consolidation is invisible; an opt-in "review before promote" tool would help |
| Per-tool fine permissions | Allow most of runtime but block specific tools (no dd, no mkfs) |
| Soft-warning at 5min | Long-running agents should signal before timeout, not just at it |
| Built-in rate limiting | Currently webhook rate limits are operator-configured; should be on by default |
These are refinements, not rewrites. The architecture's bones are right. The 12 decisions above I'd repeat without hesitation.
Across all 12 decisions, one thread runs through: bias toward what the operator can read, edit, debug, and trust, even when the alternative is faster or smaller.
| Trade | Cleverness side | Legibility side (OpenClaw's choice) |
|---|---|---|
| Memory storage | Database (faster queries) | Markdown files (readable, editable, gittable) |
| Routing | AI-driven (flexible) | Static rules (reproducible) |
| Agent splitting | Auto-cluster of micro-agents | Operator-declared per-agent profiles |
| Pruning | ML-ranked relevance | Cache-TTL tool-result pruning |
| Heartbeat triggers | Fully adaptive scheduler | Explicit duration config + HEARTBEAT_OK |
| System prompt | Heavily compressed | Readable, sectioned, file-loaded |
The "cleverness side" wins on benchmarks. The "legibility side" wins on operability over time. An agent you can't read is an agent you can't operate, and an agent you can't operate is one you'll abandon.
This isn't unique to OpenClaw. Every AI agent architecture faces this tradeoff. OpenClaw is one answer; there are others. The point is to recognize the tradeoff explicitly.
A test of architectural understanding: can you explain each subsystem in one sentence?
| Subsystem | One-sentence explanation |
|---|---|
| Runtime | The 24/7 process where agents live |
| Message flow | The 8 deterministic stages between "send" and "reply" |
| Agent loop | The reason-act-observe cycle that lets an agent investigate, not just answer |
| Memory | Three layers (logs / refined / identity) with explicit promotion |
| Context | The model's working space, managed by compaction and pruning |
| Workspace | Markdown files and subfolders that make the agent's identity portable, with config/auth/session state outside the workspace |
| Multi-agent | Determined splits along three signals, coordinated by binding + DMs + spawns |
| Sessions | The unit of working memory; persistence is what survives a restart |
| Heartbeats | The pulse that lets the agent act without prompting |
| Cron | Specific scheduled work, distinct from heartbeats |
| Webhooks | Reflexes for external events |
| Security | Three concentric layers: who can reach, what they can do, assume model untrusted |
If you can read this table and nod at each line, you've internalized the architecture. That's enough to start operating real agents responsibly.
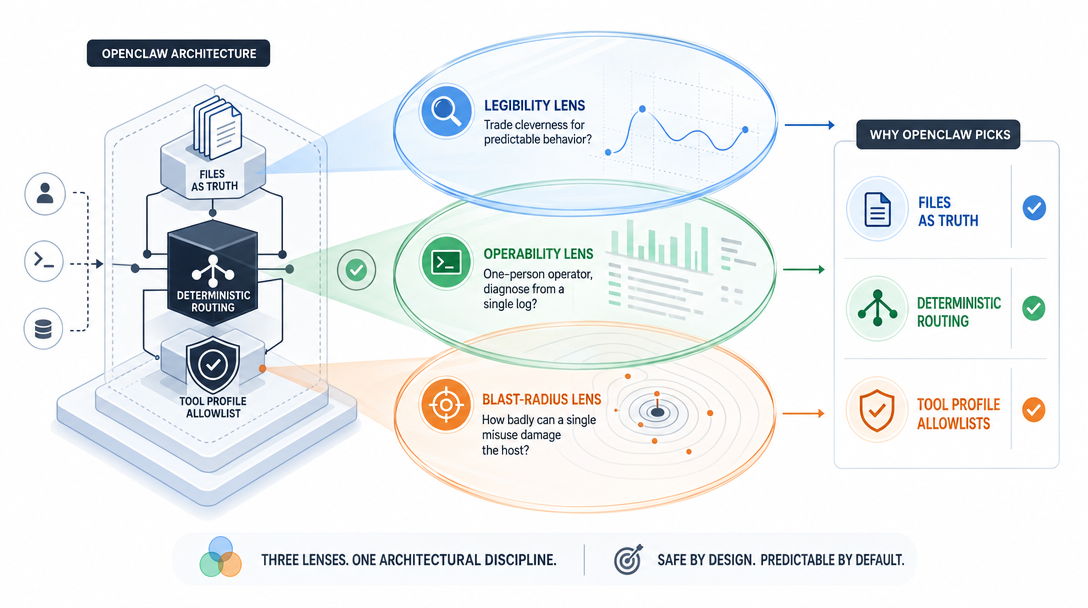
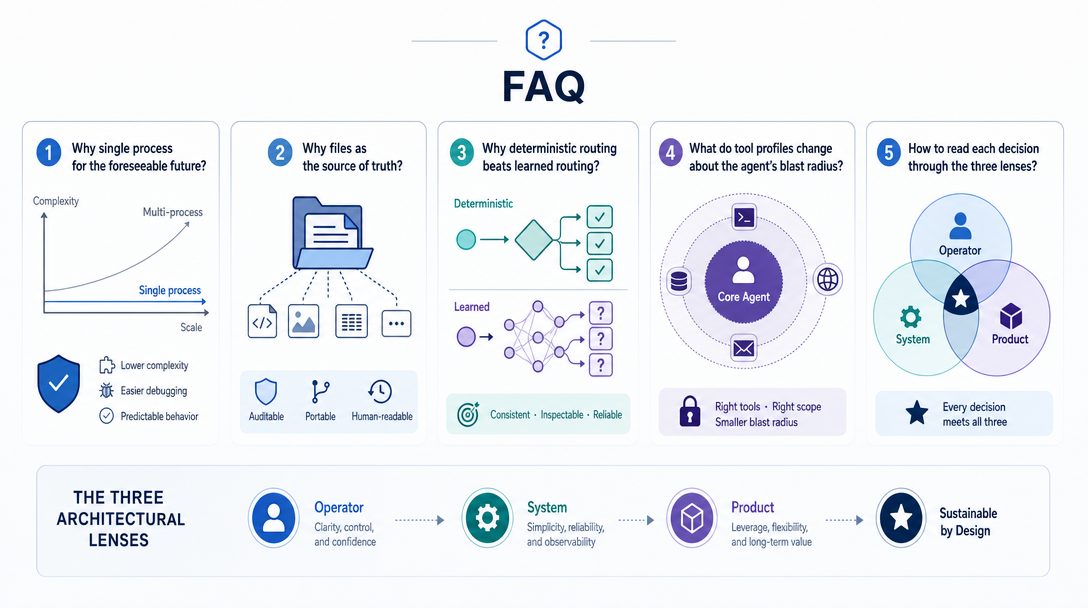
Beyond the 12 specific decisions, three reusable lenses helped me evaluate every design choice in OpenClaw, and they're transferrable to any AI agent architecture.
For every piece of state, memory, configuration, routing, permissions, ask: can the operator open a file and read what's there in plain language? If yes, the design is operable. If no, the design is "magic" and the operator is trusting it on faith.
OpenClaw passes this test almost everywhere. SOUL.md is plain. MEMORY.md is plain. Binding rules are plain config. Permissions are declared. The places where this test fails are the candidates for redesign, for example, the LLM's compaction summarization is opaque, which is why memoryFlush exists as the legibility layer above it.
When something goes wrong, can you trace exactly what happened? The trace doesn't have to be pretty, but it has to exist and be greppable. Stage-by-stage logging in the agent loop, JSONL traces of tool calls, audit logs on exec — these are the "inspect the path" infrastructure.
OpenClaw passes this lens because of the deterministic-routing decision. Every message has a binding rule that decided its agent, which has stages whose traces show what happened. The day a routing problem occurs, the path is in the log. Without this lens, debugging becomes guesswork; with it, debugging becomes reading.
Every architecture decision trades short-term ease for long-term operability, or vice versa. AI routing is shorter-term ease (no rule table to maintain) but longer-term pain (unfixable bugs). File-based memory is shorter-term cost (slower queries) but longer-term ease (portable, version-controlled, editable).
OpenClaw biases toward the longer-term operator. Most decisions cost a little extra setup time and pay off in months 3, 6, 12 of running the agent. The architectures that survive are the ones that are still pleasant to operate in year two. The architectures that die are the ones that felt great in week one and accumulated drift afterward.
These three lenses give you a way to evaluate any agent design, including ones that aren't OpenClaw, without needing to memorize a checklist. Read it; inspect it; long-horizon. The architectures that pass all three tend to be the ones worth investing in.
If you're about to build with this architecture, save yourself my mistakes.
Auto-tuning thresholds, ML-ranked context pruning, adaptive heartbeat intervals. Each "auto" added hidden state I couldn't debug. I ripped them all out. Boring beats clever for runtime infrastructure.
"Get it working first, lock it down later." I never finished phase 2. Security retrofits are 10x harder than security from day one. Permissions, allowlists, audit logs, all day one.
Built 12 agents thinking specialization would make each one sharper. Coordination cost killed the gain. Settled at 6 agents and they're each better than the 12 were. Fewer, sharper agents beats more, dispersed ones.
Disabled it because it cost tokens. Lost rules every time the conversation crossed the threshold. Re-enabled. Compound forgetting is much more expensive than the flush itself.
Then it wasn't. I had to learn the multi-agent split signals after I'd painted myself into a corner with one agent doing too many things. Single-agent is the right starting point but not the right end state.
If I could send a single page back to my year-ago self when I was about to install OpenClaw for the first time, this is what I'd write:
Trust the defaults. The current heartbeat defaults (30m, or 1h for Anthropic OAuth/token auth), the 600-second timeout, auto-compaction, and memoryFlush buffer were chosen by people who ran more agents than you have. Don't tune them in week one. Live with them for a month. Then tune one parameter and live with that for another month. Most "I want to optimize this" instincts are premature.
Read your own files. SOUL.md, MEMORY.md, AGENTS.md, they're plain text for a reason. Read them weekly like you'd read your own bank statements. The agent's behavior tracks what's in those files, not what you remember writing in them.
Don't grant full permissions. Even to your "main" agent, even for "convenience." Start with coding or messaging and add capabilities when you measure real need. The retrospective post-mortem of any agent incident always concludes with "we should have started with less permission."
Use the right silent token everywhere it fits. Heartbeats should return HEARTBEAT_OK; scheduled checks and sync agents can use NO_REPLY when they do useful work but have nothing to report. The default for "everything is fine" should be silence. Three days of quiet runs and one alert is far more useful than 26 "all good" messages and one alert that gets buried.
Put the workspace in Git on day one. Free, easy, and the day you make a bad SOUL.md edit you'll be glad you can revert. I went two months without it. Don't be me.
The workspace is the agent's home. Files-as-source-of-truth is the load-bearing decision, but it is not the whole runtime: auth, config, sessions, and task state live under OpenClaw's own directories. Treat the workspace folder like real working code. Read it. Diff it. Commit it. Six months from now, you'll thank yourself for the discipline.
Boring beats clever. When the runtime offers you a deterministic mechanism (binding rules, cron, permission groups) and a clever alternative (AI routing, smart scheduling, dynamic permissions), pick boring. Boring debugs in five minutes. Clever debugs in five hours.
That's it. The rest of the architecture is consequence of these principles. Internalize them and the 12 design decisions stop being a list to memorize and become a perspective you carry into every agent design conversation.
Want to apply the lessons to your own setup tonight? Here's the path.
Half an hour of structured audit beats a year of accidental drift.
| Decision | Ask this | Watch out for |
|---|---|---|
| Single process | Boot < 1 second? | Microservices = startup tax |
| Files as truth | Can you cat your agent's identity? |
Database-only memory = not portable |
| Deterministic routing | Static binding table? | AI routing = unfixable bugs |
| Three-tier memory | SOUL / MEMORY / logs separated? | One big file = hoarding |
| Embedded agents | All in one process unless special case? | Process-per-agent = RAM bloat |
| ReAct loop trace | Per-round trace logged? | No trace = divination |
| Permission groups | Each agent at minimum? | full everywhere = blast radius |
| Gateway on localhost | 127.0.0.1 binding? | Public exposure = abuse magnet |
| 600s timeout | Matches actual job profile? | 60s = legitimate work killed |
| Silent responses | HEARTBEAT_OK for heartbeat, NO_REPLY for non-heartbeat quiet work? |
Wrong token = noisy agents |
| Heartbeat cadence | agents.defaults.heartbeat.every understood? |
Assuming old 55m default = wrong operations |
| Language choice | TypeScript / JS plugins? | Match your team's skills |
In 90 seconds:
"Each agent has a workspace of Markdown files and subfolders, while runtime config, auth, sessions, and task state live under OpenClaw's own directories. The runtime is one process that loads those workspaces and gives agents a loop where they think, call tools, and reply. Memory has layers, daily logs, refined notes, and identity, with rules for promoting facts up the layers. Multiple agents are coordinated by a static binding table, three communication mechanisms (files / DMs / spawns), and per-agent permissions that bound the blast radius. Security is three layers: who can reach, what they can do, and the assumption that the model itself is not trustworthy. The whole thing is biased toward making behavior legible: you can read what the agent believes, edit it, version it, and debug it. Cleverness is rejected when it would hide state. Boring is the feature."
If you can give that 90-second pitch and someone walks away understanding what an OpenClaw-style runtime is, the architecture is doing its job: it's communicable, not magical.
What this does: Lists an agent runtime's planned architecture decisions, scores each on the "legible over clever / complexity forced?" test, names each cost and whether it's paid willingly, and flips any decision that adds unforced complexity or silently trades observability for performance.
Based on: AI Agent Architecture: 12 Design Decisions Behind OpenClaw — https://aiworkflowpro.com/openclaw-design-retrospective/
Time to run: ~5 minutes
Copy this prompt into Claude Code, ChatGPT, or any AI assistant:
ROLE: You are an Agent Architecture Decision Auditor. Your job: check each architecture decision in an agent runtime against the legible-over-clever bar — refusing complexity until it is forced, and never silently trading observability for performance.
CONTEXT — LEGIBLE-OVER-CLEVER DECISION METHOD:
AI agent architecture is a pile of tradeoffs. OpenClaw's twelve decisions all trade clever for legible — single process over microservices, files over databases, deterministic binding over AI routing, three-tier memory over one big file — and the runtime got portable, debuggable, and writable by refusing complexity until it was forced (twelve calls, ten in the direction of less). Each decision has a cost, paid willingly because the alternative trades observability for performance. The test for any architecture decision: does it trade clever for legible, is the complexity forced (not speculative), and is the cost named and accepted — not hidden?
INPUTS (fill in before running):
- RUNTIME_GOAL: [What the agent runtime must do — scale, one-operator vs team]
- DECISIONS: [The architecture decisions you are making — or "blank, propose the legible defaults"]
- CONSTRAINTS: [Must be portable / debuggable / writable / observable]
- COMPLEXITY_TOLERANCE: [low (refuse until forced) / high]
METHOD — 4 STEPS:
Step 1 — List the Architecture Decisions
From DECISIONS and RUNTIME_GOAL, list each planned decision (process model, state store, routing, memory, agent model, loop, tools, gateway, timeout, silent responses, heartbeat, runtime language). Where blank, propose the legible default.
Step 2 — Score Each on the Legible-Over-Clever Test
For each decision, score 0–2: 2 = trades clever for legible and complexity is forced; 1 = defensible but a closer call; 0 = adds unforced complexity or silently sacrifices observability for performance. Flag every 0.
Step 3 — Name Each Cost and Confirm It Is Paid Willingly
For each decision, state the cost (what you give up) and confirm it is accepted openly — not hidden. OpenClaw pays each cost willingly because the alternative trades observability for performance; match that bar.
Step 4 — Resolve the Failures
For every decision scoring 0, restate it in the legible direction (single process not microservices, files not databases, deterministic not AI-routed) unless CONSTRAINTS force the complex choice. Cut any complexity that is not forced.
RULES:
- Never add complexity before it is forced — the runtime stays portable, debuggable, writable by refusing it.
- Never silently trade observability for performance — if you make that trade, name the cost and pay it openly.
- Never let a decision stay at "clever" when a legible option meets CONSTRAINTS — flip it to the legible direction.
OUTPUT FORMAT:
Output a markdown report with:
1. Decision Inventory — the planned (or proposed) decisions
2. Legible-Over-Clever Scorecard — markdown table, columns: Decision | Score (0–2) | Clever or Legible?
3. Cost Accounting — markdown table, columns: Decision | Cost | Paid Willingly?
4. Resolutions — each score-0 decision restated in the legible direction
Save as @templates/openclaw-design-retrospective.md and run when designing or reviewing an agent runtime's architecture.
Files-as-source-of-truth. Every other decision flows from it: portability, version control, modular fault tolerance, and the ability to read what the agent believes about itself. If you only remember one thing, remember that the workspace is the agent's home, while runtime state lives under OpenClaw's config and session directories.
Single-process is faster to boot, cheaper in memory, and dramatically easier to debug. Microservices win at scale, but at the scale most operators run (1-10 agents on one machine), the coordination overhead of microservices outweighs every benefit. OpenClaw bets on the single-operator scale.
Probably the cron and webhook layers, they accumulated as features, not as a coherent design. Native MCP would also be more central. Most other decisions hold up: file-based identity, deterministic binding, three-tier memory, layered security.
Because legibility is what makes the runtime operable for years. Cleverness compounds into hidden state, which compounds into bugs you can't trace. An operator can't trust what they can't read. The whole architecture is shaped by the constraint that everything important must be inspectable.
Any AI agent runtime faces the same tradeoffs. The decisions in this article are not OpenClaw-specific, they're examples of the deeper question "do we trade observability for performance?" Every agent designer answers it; OpenClaw's answer is to bias toward observability.
Twelve decisions. One unifying thread: bias toward legibility, even when cleverness wins on the benchmark.
A chat product hides architecture entirely, you have no idea why it does what it does. An agent runtime makes architecture readable: every decision is a config file, a binding table, a Markdown file, a permission grant. Legibility is what lets you trust the agent for a year. Cleverness gets you hyped for a week.
Six months from now, the agent runtimes that operators are still happily running will be the ones whose architectures could be explained in 90 seconds. The clever ones will have been replaced. Bet on boring, bet on readable, bet on legible. That's the whole architecture in one sentence.
OpenClaw Deep Series · Part 10 of 10 · The End
Prev ← Part 9: OpenClaw AI Agent Security, Channels and Permissions
Full series → /tag/openclaw/
— Leo
One last thing. This is the last article in the OpenClaw Deep Series. Ten articles, fifty thousand words, dozens of tables, hundreds of small lessons. If you've read all ten, you know this architecture better than 95% of people who've ever installed an agent runtime. The remaining 5% is what you learn by running a real agent for six months, the small surprises, the personal preferences, the operations that only show up under load. Go run one. Watch it for a quarter. Come back to these articles when something surprises you, and the right answer will usually be in here. The agent that lasts is the agent whose operator understands its architecture. Welcome to the small club.
Three deliberate omissions worth naming, so you can decide whether to chase them next.
Performance benchmarking. I do not chart latency or throughput numbers in this article, because the right benchmarks depend heavily on your model choice, channel mix, and tool ratios. The honest path is to instrument your own agent for a week, then optimize the top three contributors. Generic benchmarks would be misleading.
Multi-tenant isolation at the company scale. Everything here assumes a personal or small-team runtime. Running OpenClaw for hundreds of users across multiple paying tenants raises a different set of questions, billing isolation, per-tenant quotas, secret partitioning, that the codebase does not solve out of the box today.
Cross-runtime portability. OpenClaw concepts map onto other agent runtimes, but the file formats and config keys do not. If you switch runtimes, expect to rewrite the workspace files, not just rename them. The thinking transfers; the syntax does not.
If any of those three matters for your situation, treat this article as the foundation, not the finish line.
HEARTBEAT_OK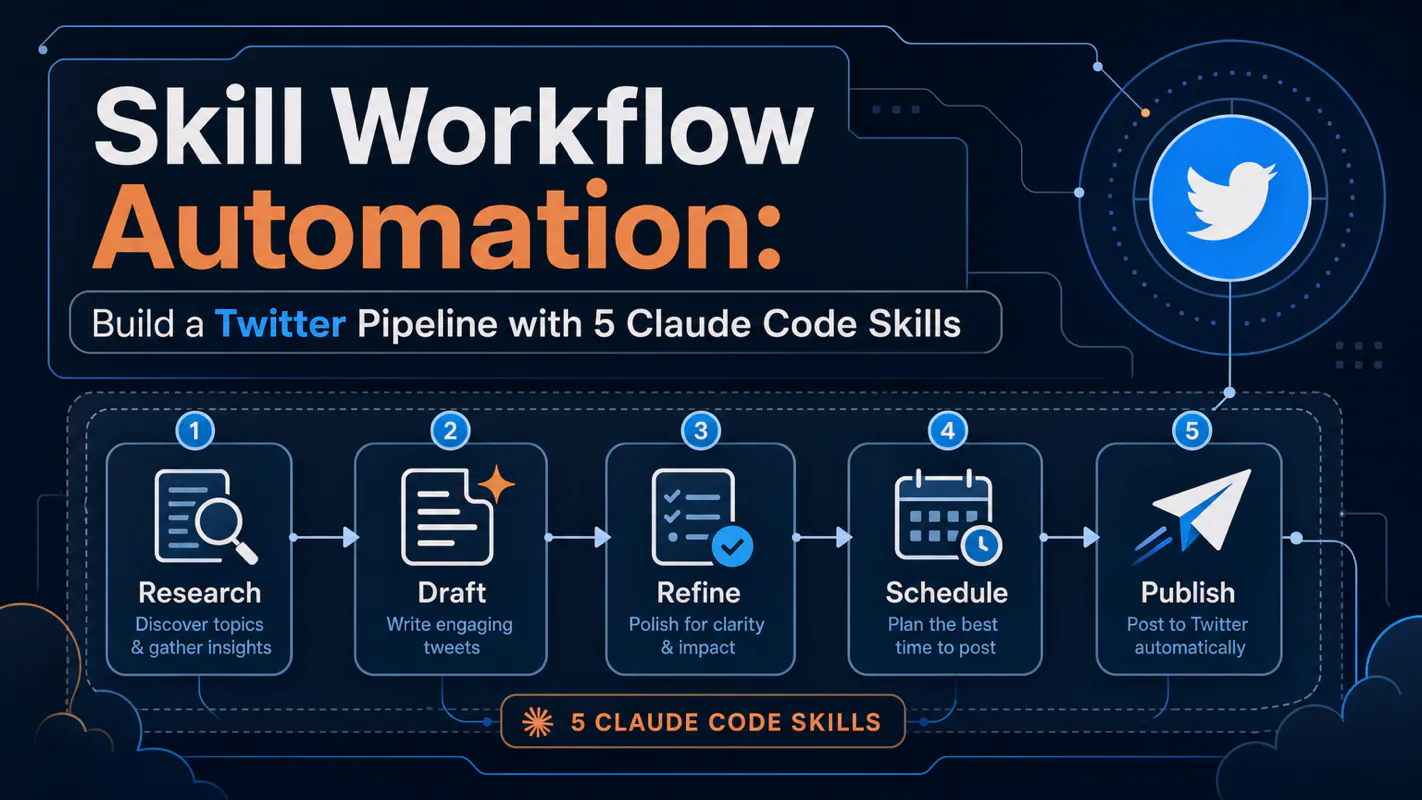
Build a fully automated Twitter content pipeline using five Claude Code Skills. This hands-on tutorial covers persona cloning, content sourcing, AI writing, image generation, and scheduled publishing — all running unattended. Learn the single-responsibility principle for Skill design, file-based dat

Most developers spend 60% of their Skill development time debugging. The Quality Loop framework cuts that to under an hour through dual-phase detection, four-layer verification, and SubAgent self-repair. Here is the complete system I built after testing 20+ Skills.

Your AI agent can call Claude Code. But can it do that at 3 AM without crashing, hanging, or silently failing? I built a Bridge middleware that handles process management, timeouts, and automatic recovery -- so my 10 agents run Skills overnight while I sleep.
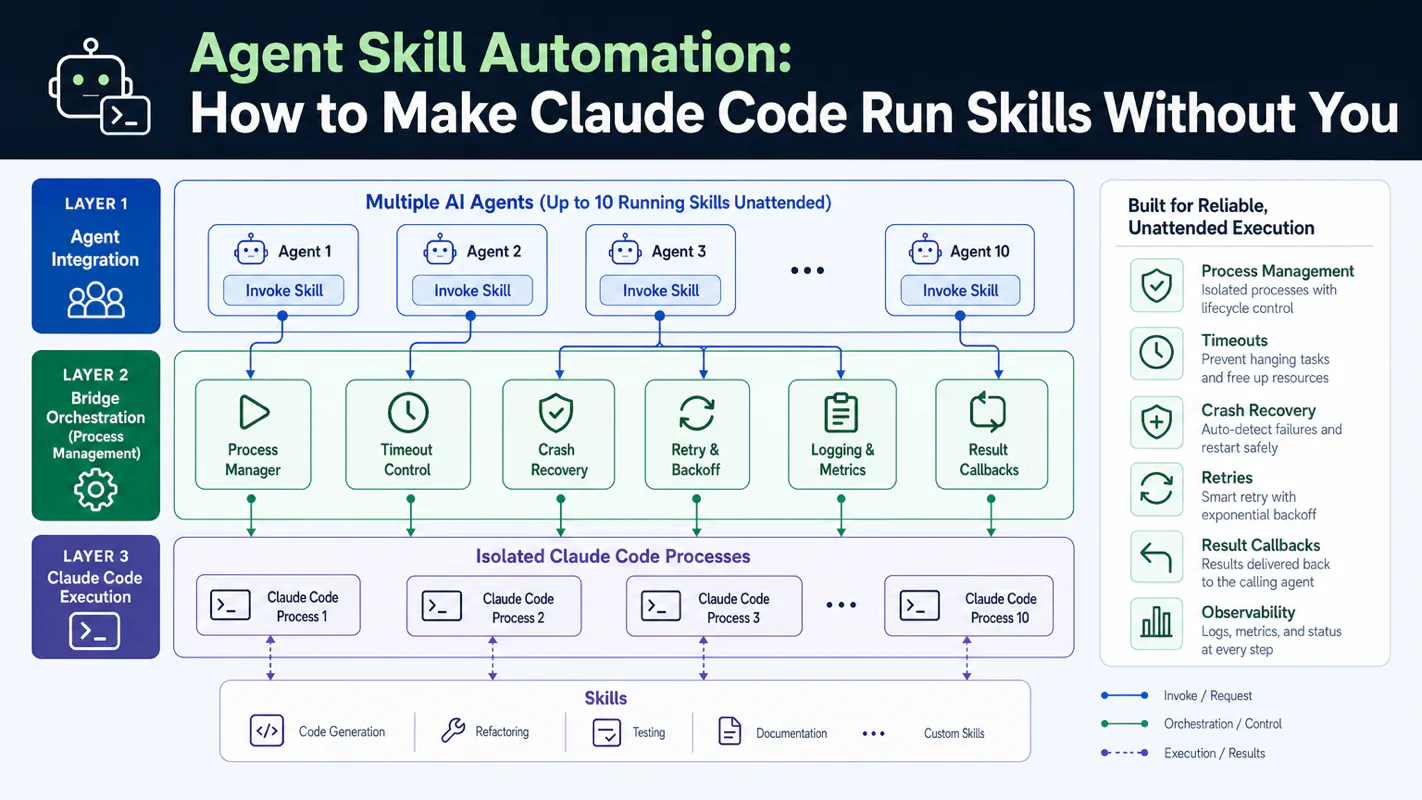
Your AI agents can invoke Claude Code, but reliable Skill execution demands process management, timeouts, crash recovery, and result callbacks. This tutorial breaks down the Bridge three-layer architecture that keeps 10 agents running Skills unattended.
Get updates on new AI tools, workflows, and behind-the-scenes progress from Leo.