Hermes Agent landed with 42K GitHub stars and a tagline that hooked every OpenClaw user I know: out-of-the-box behavior that feels like a week-tuned OpenClaw setup. I spent a week stress-testing it through six rounds — memory, tool use, Skill self-learning, multi-agent coordination, security posture
Most Claude Code users plateau because they ask the same way they Google. The art is the opposite — give the agent context, intent, and format, and it goes from chatbot to mentor. Here are nine moves that turn day-one prompts into the kind of asks that get senior-engineer-quality work back, includin
A working OpenClaw deployment with one CEO agent and nine specialist agents — content, growth, design, ops, finance, customer success, research, automation, review — running across Discord channels with persistent workspaces, cross-department message-passing, and Cron scheduling. This is the full bu
OpenClaw Multi-Agent Systems: When to Split Agents
More agents is not better. Splitting too early adds coordination cost. Splitting too late lets one agent's identity smear across responsibilities. Three signals tell you it's time, four tools tell you how to do it cleanly.
OpenClaw Multi-Agent Systems: 3 Signals for Splitting Agents
TL;DR: Multi-agent systems work when you split for the right reasons. Three signals tell you when (different responsibilities, different permissions, different context budgets), four mechanisms tell you how (binding, three-tier communication, model tiering, auth isolation). Splitting too early adds coordination cost; splitting too late lets one agent's identity smear across jobs. Get the timing right and 5-10 agents on one machine outperform a single large agent.
Everyone says "more agents is better." Actually, splitting too early doubles your maintenance and saves nothing. The right question is not how many agents you can run; it is when one agent stops earning the complexity of staying single.
If you already run three or more agents, skip ahead to §6 for auth isolation. If you are still on one agent and feeling fuzzy, read on.
You start with one agent that does everything. Replies on Telegram. Writes drafts. Watches the server. Summarizes email.
Six weeks in, things start feeling fuzzy. The replies get a little less crisp because the writing-mode prompts and the server-watcher prompts are rubbing shoulders. The agent runs exec for server work and you wonder if you really wanted that same exec access while it's drafting an email. The token bill creeps up because every call loads tools, instructions, and memory for all four jobs even when only one is happening.
Honestly? Try this question: at what point should you stop adding to one agent and start splitting into many?
The naive answers are extremes. "Always one agent", easy to manage, but every job dilutes the others. "Always many agents", clean separation, but coordination costs explode and you lose the integrative judgment a single agent can have.
The right answer is in the middle, and it depends on three specific signals. The rest of this article walks the signals, the four mechanisms OpenClaw provides for multi-agent coordination, and the five mistakes I made before settling into a stable 6-agent setup.
If "agent runtime" still feels new, two short maps to keep open:
The series footer below maps every part to its slug.
1. The intuition trap: "more agents is better"
Most people intuit that more specialization is better. If one agent does four jobs, surely four agents each doing one job will be sharper.
That intuition is wrong in two specific ways.
Coordination has a cost. When two agents share state (a project, a user preference, a deadline), keeping them in sync is work. Either you write code to sync them, or you accept drift, or you re-share context every time. Each of these costs more than the savings from specialization until the agents are doing genuinely different things.
One agent has integrative judgment. A single agent that knows about your server, your drafts, and your email can spot connections — "the deploy failure email is related to the cron job that ran at 02:14." Split into three agents and that connection requires explicit hand-off logic.
The right framing: don't add agents because more is better. Add agents because the responsibilities have genuinely diverged.
2. The three signals: when to split
Here is why this matters: agent count is the single biggest lever on operational cost and clarity. Two well-scoped agents are cheaper to run and easier to debug than one agent with four hats; six agents that should be three are the opposite.
If exactly one of these is true, you don't need to split. If two or three are true, you should.
Signal 1: responsibilities have genuinely diverged
Different jobs imply different defaults, different vocabulary, different success criteria. A debugger and a writer are different. A server-watcher and a personal assistant are different.
The test: if you wrote a SOUL.md for the unified agent, would it have contradictions? "Default to concise replies" (good for the writer) collides with "default to verbose investigation" (good for the debugger). When SOUL.md can't be written without "depending on which mode you're in" disclaimers, the modes want to be agents.
Signal 2: permission needs differ
If one job needs exec and another job only needs messaging, keeping them in one agent means the messaging side is over-permissioned. Prompt injection on the messaging channel could trigger arbitrary shell commands.
The test: if you draw the smallest permission set each job actually needs, are they noticeably different? If the writer agent only needs fs and messaging while the debugger needs runtime (exec), splitting buys you real security. The blast radius shrinks to each agent's actual job.
Signal 3: context budgets are fighting
Different jobs accumulate context at different rates. A debugger might need 40K tokens of recent log output; a writer might need 10K tokens of style references. Cramming both into one context window means each is compromised.
The test: run /context detail after a real task. If the breakdown shows two task types each pulling 30%+ of the window in different directions, splitting buys you twice the working space, each agent's context is dedicated to its own job. (See Part 5 for context economics.)
3. Binding: deterministic routing, not AI routing
Once you have multiple agents, the gateway needs to decide which agent receives an incoming message. The naive design is "let an LLM read the message and pick the right agent." OpenClaw deliberately doesn't do this.
The reason is debugging. Routing is the part of the system you debug most often when things go wrong. If routing is non-deterministic, driven by a model whose decisions depend on prompt phrasing, context, time of day, you can't reproduce a routing failure, can't predict the path, can't audit who saw what.
OpenClaw uses deterministic binding rules. A binding table maps {channel, condition} → agent. The first matching rule wins. The rules are plain config:
Condition
Example
Agent
Channel ID
Discord #leadership
CEO agent
Guild ID
A whole Discord server
Default agent for that server
Peer kind
direct vs. group
Different agent for DM vs. group
Platform
telegram vs. discord
Different agent per platform
If a message routes to the wrong agent, you read the binding table, find the rule that matched, fix it. Five-minute debug. AI routing would have made the same debug a 30-minute investigation with no guarantee of repeatability. Determinism here pays off every single time something goes wrong.
I tried writing a "smart router" agent once that read incoming messages and dispatched to specialists. Stopped after two weeks. The router was 90% accurate, but the 10% misroutes were impossible to fix because they depended on the model's mood. Deterministic binding is 100% accurate by construction. Boring beats clever for routing.
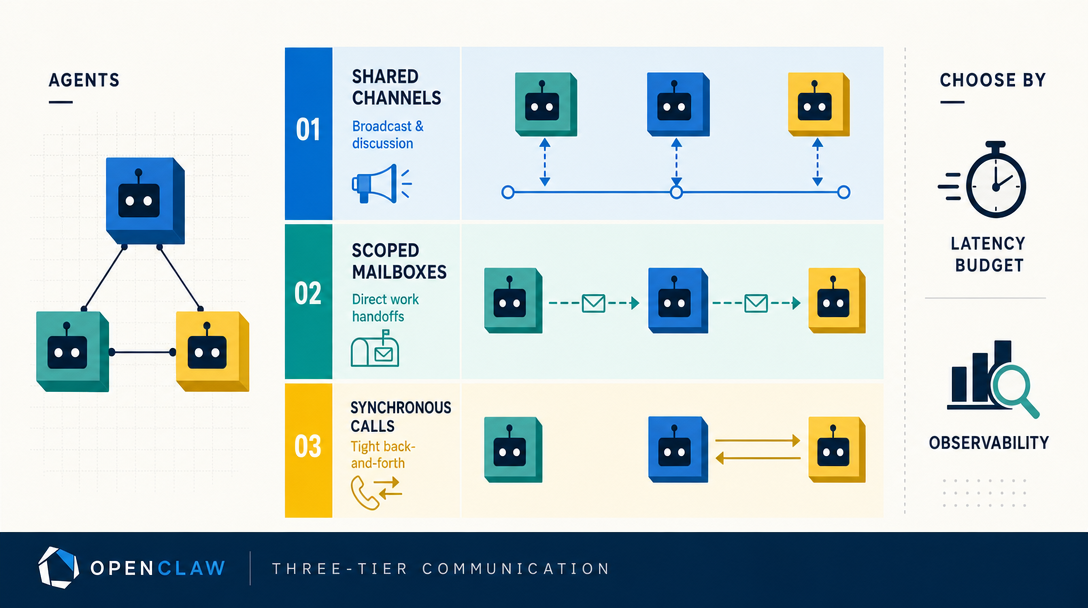
4. Three-tier communication: how agents talk
Once messages are routed, agents sometimes need to talk to each other. OpenClaw exposes three communication mechanisms with different trade-offs.
Tier 1: Shared files (slowest, simplest)
Both agents read the same file. One writes; the other reads on its next turn.
This is the lightest mechanism. No protocol, no message passing, no concurrency primitives. Just a file. The trade-off: agents see each other's updates only on their next call, so timing can be off by minutes.
I use shared files for slow-evolving state — current project list, team-wide preferences, weekly priorities. The minute-scale latency is fine for that kind of data.
Tier 2: Tool-mediated DMs (medium speed)
Agent A uses the message tool to send to a channel where agent B is bound. The runtime delivers it like any inbound message.
agent A: message --channel internal-research --to research-agent "fetch latest stats on X"
[runtime delivers to research-agent on next inbound poll]
research-agent: ... runs query, replies in same channel ...
agent A: ... reads reply on its next inbound check ...
This is the workhorse mechanism. Async but reliable, audited (every message hits the gateway log), bounded by the same routing rules as human messages. Latency is seconds, not minutes.
I use tool-mediated DMs for request/response between agents — "writer asks researcher for a fact" or "monitor asks deployer to restart a service."
Tier 3: Spawn pattern (fastest, most ephemeral)
Agent A spawns a sub-agent to do a specific job, waits for the result, the sub-agent dies.
agent A: spawn analyzer --workspace ~/.openclaw/workspace-analyzer --task "summarize this 3000-line log"
[runtime starts analyzer in process, runs task, returns result]
agent A: ... continues with the summary in hand ...
Sub-agents inherit nothing implicit. They get a workspace path, a permission profile, and the task. They report back a result. They terminate. Sub-agents are the right tool when you need a one-off, deeply-scoped piece of work that shouldn't pollute the parent's context.
I use spawns for expensive specialized work — large file analysis, multi-step research, anything that would otherwise blow the parent's context. The spawn's bloated context dies on completion; the parent stays clean.
When to use which
Use case
Mechanism
Why
"What's our active project list?"
Shared file
Slow-changing, both agents read regularly
"Researcher, fetch X for me"
Tool-mediated DM
Request/response, audited
"Run this 3000-line analysis without polluting my context"
Spawn
Ephemeral, isolated
"Both agents need to react to the same external event"
Both bind to the same channel
Pub-sub via gateway
The key principle: pick the lightest mechanism that fits. Files for slow shared state, DMs for explicit request-response, spawns for ephemeral specialist work.
5. Model tiering: don't use Sonnet for everything
Before splitting, one agent loaded all tools on every call. After, each agent loads only the tools it needs. The writing agent never sees exec; the server-watcher never sees draft history.
When you have multiple agents, model selection becomes a per-agent decision. Different jobs benefit from different model tiers.
Tier
Strength
Best for
Sonnet 4.6 (as of 2026-04)
Reasoning, long-context coherence
Main agent, complex investigations, drafting
Haiku 4.5
Speed, cost (≈ 1/5 of Sonnet)
Routing, simple replies, structured extraction
Opus 4.7
Deepest reasoning, expensive
One-shot heavy tasks (architectural decisions, large doc analysis)
A six-agent setup might have:
Agent
Model
Why
Main assistant
Sonnet
Conversational, integrative
Server watcher
Haiku
Patterns are stable, structured output
Email triage
Haiku
Classification task, simple reasoning
Researcher
Sonnet
Needs deep reasoning over long sources
Writer
Sonnet
Long-form generation
Architect (rare)
Opus, on-demand
Expensive but only invoked for big decisions
Mixing tiers is the second-biggest cost lever after prompt caching. Running every agent on Sonnet when half could be Haiku doubles your bill. I had a six-agent setup that I ran on Sonnet for two months because "consistency feels safer." Switching the watcher and triage agents to Haiku cut my monthly bill 40% with no measurable quality drop on those tasks.
6. Auth profile isolation: no inheritance
When agent A spawns agent B, what permissions does B have?
The wrong answer: "whatever A has." That would mean a permission audit on the spawning agent leaks into all sub-agents. Prompt injection on a sub-agent suddenly has the parent's full power.
OpenClaw's answer: B has exactly what B's own auth profile declares. No inheritance.
Spawning agent
Sub-agent
Sub-agent permissions
Main agent (full permissions)
Researcher (declared web only)
Only web
Main agent (full permissions)
Analyzer (declared fs read-only)
Only fs:read
Researcher (web only)
Sub-researcher (declared web only)
Only web
The principle: each agent's permissions are stated explicitly in its auth profile, and that profile is the only thing that grants permissions, regardless of who spawned it.
I made the wrong assumption early on, I figured a sub-agent spawned from my "full" main agent would have full access. Wrong. The sub-agent had only what its workspace declared, which was messaging only. Tried to run exec, got refused. Spent 20 minutes debugging until I read the auth profile spec. Per-agent isolation is the right default; don't fight it.
6.5 The diagnostic question I run before every split
Before I split an agent, I run one question through three lenses: scope, blast radius, and audit.
Scope. Are these two responsibilities asking for fundamentally different mental models? A writing agent and a server-watcher agent are not just different tasks; they think differently. The writing agent needs persona, voice, and editorial judgment. The server-watcher needs caution, exec discipline, and incident calm. One prompt cannot honestly be both, and a model fed both prompts will quietly average them.
Blast radius. Does one job carry risks the other does not? A drafting agent that runs exec is a security smell, even if it is convenient. Splitting cleanly separates the agent that can edit your filesystem from the agent that talks to your customers. Each gets the smallest permission set that does its job, and a bug in one cannot reach the other.
Audit. When something goes wrong, can you tell which job caused it? With one agent doing four jobs, every log line needs context to understand which workflow it belongs to. With four agents, the log itself answers the question. Audit clarity is a feature, not a side effect.
If two of three say split, I split. If only one, I keep the agent single and add scope discipline instead. The signal is rarely zero, and rarely all three; it is usually one or two, which is why this is a judgment call, not a rule.
7. The 5 mistakes I made setting up multi-agent
If you're about to split your single agent into many, save yourself my mistakes.
Mistake 1: I split too early
After two weeks of one agent, I thought "I should split this into specialists." So I made five agents from day three. Coordination cost was higher than the specialization gain. None of the agents had enough context to be coherent. Don't split until you've felt the pain of not splitting. Six weeks of one agent showed me exactly which jobs wanted to be separate.
Mistake 2: I used AI routing instead of binding
I built a "smart router" agent that read messages and dispatched. Routing was 90% accurate. The 10% wrong routes were unfixable because they depended on the model's mood. Switched to deterministic binding. Routing went to 100%, and bugs became 5-minute fixes. The model is too clever for routing's own good.
Mistake 3: I made every sub-agent inherit `full` permissions
I figured "sub-agents do my work, they should have my power." First time a sub-agent got an injection-y prompt from a public channel, it tried to run shell commands. Lock-down was retrofit and partial. Per-agent auth profiles aren't bureaucracy; they're blast-radius control.
Mistake 4: I ran every agent on Sonnet
Two months of paying premium for jobs that didn't need premium reasoning. Switching the watcher and triage agents to Haiku cut my bill 40% with no quality drop. Match the model to the task, not to a single default.
Mistake 5: I used spawns for everything
Spawns are great for one-off heavy tasks. They're terrible for ongoing collaboration, every spawn is a fresh agent with no shared state. I tried using spawns for "researcher gets a question, replies, parent continues." Should have used a long-lived researcher agent with tool-mediated DMs. Spawns for one-shot, DMs for ongoing.
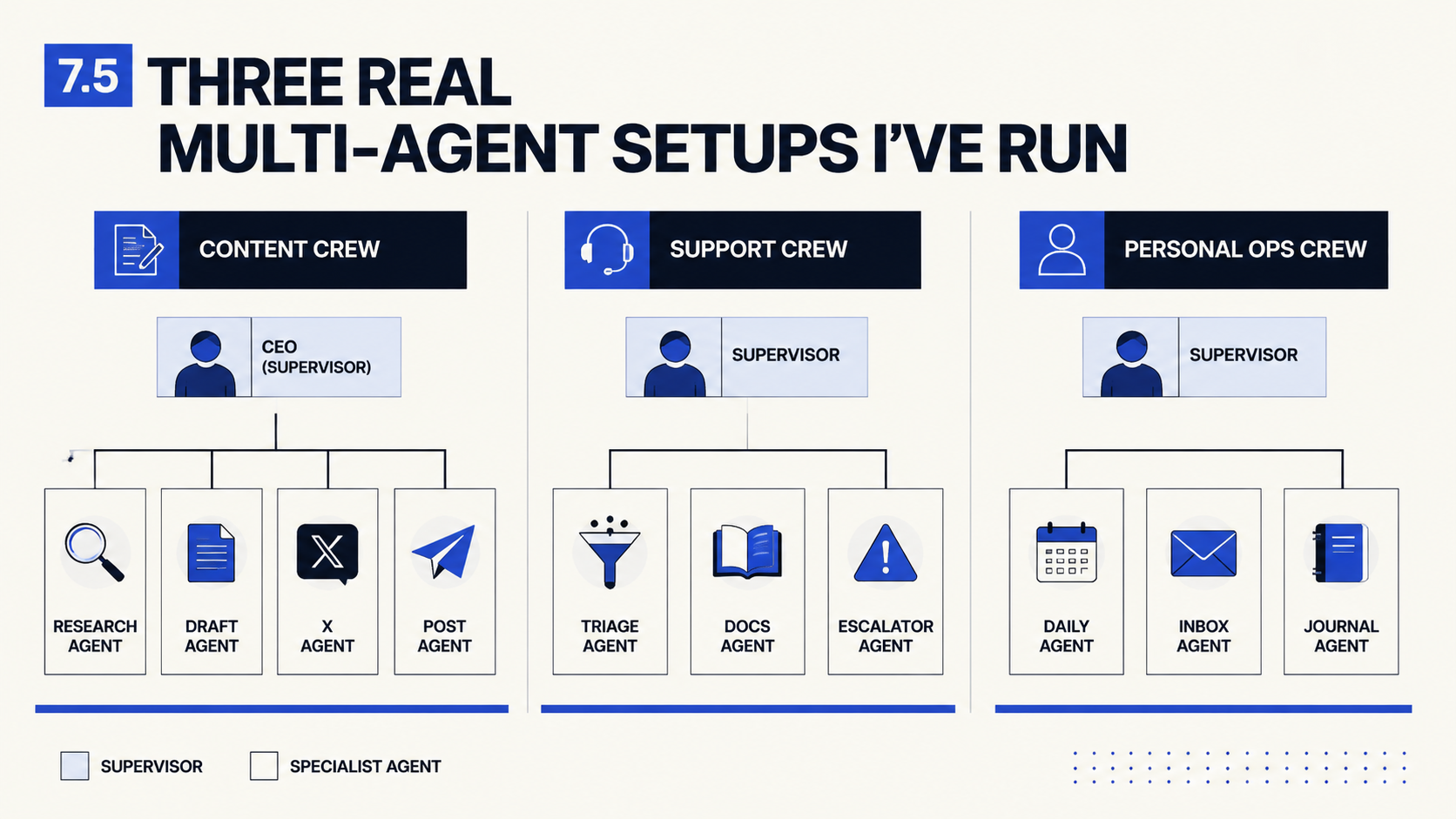
7.5 Three real multi-agent setups I've run
To make the abstract concrete, here are three multi-agent setups I've actually deployed, with what worked and what didn't.
Setup A: Solo operator's daily life (6 agents)
Agent
Job
Permissions
Channel
main
Conversational assistant
full
Telegram DM
inbox-triage
7am email summary
fs (read) + messaging
Cron-only
server-watcher
Hourly server health
runtime + messaging
Heartbeat-only
gh-watcher
Watch starred repos
web + messaging
Cron 4-hourly
discord-faq
Answer repeated questions
messaging
Discord public channel
daily-log
22:00 reflective question
messaging + fs
Cron + Telegram DM
What works: each agent has a clear, narrow role. Permissions are tight. The discord-faq agent on a public channel can never escalate beyond messaging, even with a perfect injection. What broke initially: I didn't isolate gh-watcher and it started polluting main's memory with GitHub trivia. Fix was a separate workspace, no shared MEMORY.md.
Setup B: Small team (3 agents, 4 humans)
Agent
Job
Permissions
Who can reach
team-assistant
Shared scheduling, notes
messaging + fs
All 4 humans, allowlisted
code-reviewer
PR comments
web (GitHub) + messaging
CI webhook only
incident-handler
On-call alert triage
runtime + messaging
PagerDuty webhook only
What works: each agent has a single human-or-system audience. Permissions match exactly. What broke initially: I tried to give team-assistantruntime permission "for convenience." A team member's prompt accidentally caused it to run a destructive command. Reverted to messaging + fs:read only. Convenience permissions are a security debt that compounds.
Setup C: Public-facing community bot (2 agents)
Agent
Job
Permissions
Where
community-bot
Answer FAQs, route help requests
messaging
Public Discord, allowlisted to everyone with rate limit 5/min
mod-helper
Notify moderators of escalations
messaging
DM only to mod role
What works: the public-facing agent has the absolute minimum (messaging). The mod-helper agent is unreachable from public channels. What broke initially: I conflated them as one agent thinking "fewer agents is simpler." Splitting into two cleanly isolated the public attack surface from the moderator workflow. Even with two-agent overhead, the security clarity is worth it.
The pattern across all three setups: agents specialize along the security boundary first, then along the responsibility boundary. When in doubt about whether to split, ask "would this need different permissions?" If yes, split.
8. A 30-minute path: design your first multi-agent setup
Want to set up a real multi-agent system tonight? Here's the path.
List your current agent's jobs (5 min). Write them down. Be specific. "Replies on Telegram" / "Watches server every hour" / "Drafts email replies."
Apply the three signals to each pair (10 min). For every pair of jobs, ask: are responsibilities different? Are permissions different? Are context budgets fighting? Two yeses = candidate to split.
Pick the cleanest split (5 min). The pair with the most "yeses" is your first split. Not all the splits, just one.
Set up binding (5 min). Edit openclaw.json to add a binding rule: a specific channel routes to the new agent. Don't overlap with the old agent's channels.
Create the new workspace (3 min). mkdir ~/.openclaw/workspace-{newname}. Add minimal SOUL.md + IDENTITY.md (see Part 6).
Set the auth profile (2 min). Declare the smallest permission set the new agent actually needs. Don't grant anything "just in case."
Run for a week, observe (passive). Notice if the split feels right. If yes, repeat for the next pair. If no, merge back.
Half an hour of structured thinking saves two months of trial-and-error.
Multi-agent system checklist
Decision
Ask this
Watch out for
When to split
At least 2 of 3 signals true?
"It feels cleaner" isn't a signal
How to route
Deterministic binding?
AI routing = unfixable bugs
How to communicate
Lightest mechanism that fits?
Files for slow, DMs for request, spawns for one-shot
Model per agent
Tiered by task complexity?
All Sonnet = wasted dollars
Permissions
Per-agent auth profile?
Inherited permissions = blast radius
Count
5-10 for one operator?
15+ = probably some should merge
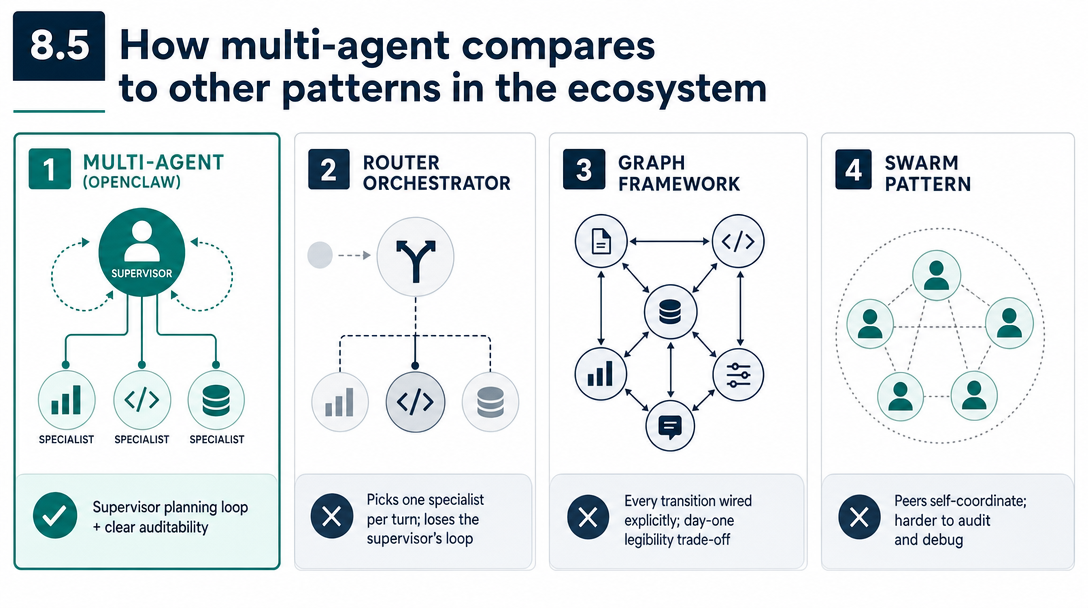
8.5 How multi-agent compares to other patterns in the ecosystem
For honesty, OpenClaw's multi-agent design isn't the only viable pattern. Three alternative shapes worth knowing:
Compare with CrewAI
CrewAI bills itself as a multi-agent framework. The shape is different from OpenClaw's: agents in CrewAI are more like roles in a Python program, orchestrated through code, with explicit "tasks" passed between them. It's optimized for short-lived multi-agent workflows triggered programmatically. OpenClaw is optimized for long-lived multi-agent setups that humans message.
Use CrewAI when: you have a deterministic pipeline that benefits from specialist roles (research → write → fact-check) and you want it programmable.
Use OpenClaw when: you have ongoing relationships with multiple agents that share state and respond to humans.
Compare with AutoGPT-style "agent of agents"
AutoGPT and similar projects often have one "manager" agent that spawns and coordinates other agents on demand. High flexibility, low predictability. The manager decides what to do, when, with whom, which means debugging is hard and behavior drifts over time.
OpenClaw's static binding + explicit spawn pattern is the opposite end of that spectrum. Less flexible. More legible.
Compare with vendor-specific "agent platforms"
Several cloud providers have launched managed agent platforms (Anthropic's, OpenAI's, AWS's). They handle multi-agent for you but at the cost of opacity and vendor lock-in. You don't see the binding rules; you don't choose the model tiering; you can't audit the trace at the level OpenClaw exposes.
Use a managed platform when: you don't want to operate the runtime and the price-per-call makes sense.
Use OpenClaw when: you want operational visibility and the freedom to tune everything yourself.
The point isn't that OpenClaw is "best", it's that multi-agent design is a tradeoff space, and different products land in different places. Knowing the choices helps you pick deliberately rather than by accident.
How I would build a multi-agent setup from scratch
The order I'd recommend:
Run one agent for a month. Don't split.
Identify the job that wants to leave first (usually a server watcher or a scheduled summarizer, they have the clearest "different" profile).
Split that one. Bind to its own channel. Give it minimal permissions.
Run for two more weeks. Observe.
If a second job wants to leave, repeat. If not, stop at two.
Cap at 5-7 unless you're absolutely sure you need more.
Each split is a decision, not a default. The compound result, after a few months, is a lean multi-agent setup where each agent is sharper than the unified one was, total cost is lower (model tiering), and security is tighter (auth isolation).
Back when I ran personal automation on n8n, "multi-agent" wasn't a concept, workflows were either one big graph or several disconnected ones. The runtime model gives you a third option: distinct identities that can route, communicate, and spawn. It's the difference between a one-person business with everything in one notebook and a small team with each role having its own desk. The team setup costs more in coordination but produces dramatically better work past a certain scale.
FAQ
When should I use multi-agent instead of one big agent?
Three signals: responsibilities are genuinely different (debugging vs. drafting), permission needs differ (one agent shouldn't touch the other's tools), or context budgets fight each other. If none apply, one agent is the right answer.
Why does OpenClaw use deterministic binding instead of letting the AI route?
Routing is a debugging concern. If a model decides which agent receives a message, you can't predict the path, can't reproduce failures, can't audit. Deterministic binding (channel ID → agent) makes routing inspectable and bug-fixing fast.
How do agents communicate in a multi-agent system?
Three tiers: shared files for slow async (each agent reads the other's MEMORY.md), tool-mediated DMs for direct request/response, and the spawn pattern for short-lived sub-agents. Pick the lightest mechanism that fits the use case.
Should sub-agents inherit their parent's permissions?
No. OpenClaw enforces auth profile isolation. A sub-agent gets exactly the permissions its own profile declares, no inheritance from the spawning agent. This is the principle of least privilege made operational.
How many agents is too many?
5-10 is usually the sweet spot for a single operator. Past 10, coordination costs rise faster than benefits. If you're running 15+ agents, ask whether some of them should merge, it's often three small agents pretending to be one large agent.
Closing
Three signals to know when. Four mechanisms to know how. One operating principle: don't split because more is better; split because the responsibilities have genuinely diverged.
A chat product hides multi-agent behind opaque "team" abstractions where you can't see who's doing what. An agent runtime makes it concrete: you can see the binding table, you can audit the message flows, you can spawn and kill on demand. Legibility is what makes multi-agent operable instead of mysterious, and operable is what makes it pay off.
One last thing. Multi-agent systems amplify whatever shape your single agent already has. If your single agent is well-structured, splitting it into specialists makes each specialist sharper. If your single agent is messy, splitting it propagates the mess into multiple agents that all share the same drift. Multi-agent is not a fix for a confused agent. Get the single agent right first. Then split when the signals justify it. Six months from now, the multi-agent setups that still work will be the ones that started from a clean SOUL.md and grew deliberately, one agent at a time.
What this article does not cover
Three deliberate omissions worth naming, so you can decide whether to chase them next.
Performance benchmarking. I do not chart latency or throughput numbers in this article, because the right benchmarks depend heavily on your model choice, channel mix, and tool ratios. The honest path is to instrument your own agent for a week, then optimize the top three contributors. Generic benchmarks would be misleading.
Multi-tenant isolation at the company scale. Everything here assumes a personal or small-team runtime. Running OpenClaw for hundreds of users across multiple paying tenants raises a different set of questions, billing isolation, per-tenant quotas, secret partitioning, that the codebase does not solve out of the box today.
Cross-runtime portability. OpenClaw concepts map onto other agent runtimes, but the file formats and config keys do not. If you switch runtimes, expect to rewrite the workspace files, not just rename them. The thinking transfers; the syntax does not.
If any of those three matters for your situation, treat this article as the foundation, not the finish line.
Hermes Agent landed with 42K GitHub stars and a tagline that hooked every OpenClaw user I know: out-of-the-box behavior that feels like a week-tuned OpenClaw setup. I spent a week stress-testing it through six rounds — memory, tool use, Skill self-learning, multi-agent coordination, security posture
Most Claude Code users plateau because they ask the same way they Google. The art is the opposite — give the agent context, intent, and format, and it goes from chatbot to mentor. Here are nine moves that turn day-one prompts into the kind of asks that get senior-engineer-quality work back, includin
A working OpenClaw deployment with one CEO agent and nine specialist agents — content, growth, design, ops, finance, customer success, research, automation, review — running across Discord channels with persistent workspaces, cross-department message-passing, and Cron scheduling. This is the full bu
AI agent security is three concentric layers: who can reach the agent, what the agent can do, and the assumption that the model itself is not trustworthy. Skip any layer and one prompt injection becomes one breach.