Hermes Agent landed with 42K GitHub stars and a tagline that hooked every OpenClaw user I know: out-of-the-box behavior that feels like a week-tuned OpenClaw setup. I spent a week stress-testing it through six rounds — memory, tool use, Skill self-learning, multi-agent coordination, security posture
Most Claude Code users plateau because they ask the same way they Google. The art is the opposite — give the agent context, intent, and format, and it goes from chatbot to mentor. Here are nine moves that turn day-one prompts into the kind of asks that get senior-engineer-quality work back, includin
A working OpenClaw deployment with one CEO agent and nine specialist agents — content, growth, design, ops, finance, customer success, research, automation, review — running across Discord channels with persistent workspaces, cross-department message-passing, and Cron scheduling. This is the full bu
Why I Only Use Brave for Search API: A 6-API Bake-Off
I tested SerpAPI, Serper, Google Custom Search, Tavily, Exa, and Brave for my AI agents — then deleted five of them. Brave wasn't the cheapest. It was the only one that owned its index, treated privacy as an engineering constraint, and shipped an AI-native LLM Context API. Here's the three-axis test
I tested SerpAPI, Serper, Google Custom Search, Tavily, Exa, and Brave for my AI agents — and deleted five of them
The reason wasn't price. It was that the other five did not own the search results they returned, which means your agent's quality lives downstream of someone else's anti-bot policy
Brave is the only mainstream search API that ticks all three boxes: independent index (35B pages, ~100M new daily), privacy as an engineering constraint, and an AI-native LLM Context API
One-line MCP install drops seven Brave tools straight into Claude Code with no fetch glue
The $5/1,000 search pricing isn't a cost question, it's a tax on builders who care about basics — and it's still cheaper than the SerpAPI tier most teams default to
I tested six search APIs for my AI agents over three months: SerpAPI, Serper, Google Custom Search, Tavily, Exa, and Brave. Five of them got deleted from the stack.
The reason wasn't price. It was that the other five all had a single fatal property in common: the search results they return are not theirs. That sentence sounds strange the first time you read it. A search API returns search results; how can they not be "theirs"? Stay with me — that one question is the entire point of this post.
This isn't a benchmark report. It's the selection log of a builder who got bitten three times before he stopped trying to make the cheaper options work. By the end of this post you'll have:
A three-axis test that resolves search-API selection in about ten minutes
The cost math for $5 / 1,000 searches, set against SerpAPI and Google Custom Search at the same volume
The one-line MCP install that wires Brave into Claude Code with no glue code
Who This Is For
You're building an AI agent that needs to search the web more than ten times a day
You've felt the pain of a search API that "just stopped working" because Google or Bing changed something upstream
You care about the difference between "we promise we won't sell your data" and "we architecturally cannot sell your data"
You'd rather spend an afternoon picking the right tool once than rewrite your search layer every six months
If you're building a one-off scraper that runs twice a week, any of the six APIs is fine. The selection criteria below kick in once your agent depends on search the way it depends on the model itself.
Whose Index Are You Actually Using?
Most search APIs on the market are running one of three business models. The model determines who actually controls the quality of every result your agent sees. Most builders pick by price and never ask the model question, which is exactly how the upstream surprise lands six weeks in.
Model 1: Their own index. Brave Search runs an independent index of about 35 billion pages, with its own crawler adding roughly 100 million pages a day. Every result Brave returns comes out of an index Brave physically owns and maintains. That's the own-the-mine model.
Model 2: Reselling someone else's index. SerpAPI and Serper, despite the names, do not have indexes of their own. They scrape the public Google search results page in real time, parse the HTML into JSON, and resell it as an API. You think you're calling an API; you're actually calling a wrapper around Google's anti-bot defenses. That's the carry-from-someone-else's-mine model.
Model 3: Licensing someone else's index. DuckDuckGo's API uses Bing under the hood. Tavily, Exa, and several others ride on Bing or Google through commercial licensing. The brand on the label is one company; the data is somebody else's. That's the rent-the-mine model.
The blunt rule of thumb: whoever owns the index decides the quality. If you're on Serper, the floor of your search quality is whatever Google did to its anti-bot stack this morning. If you're on DuckDuckGo, the floor is whatever Bing did to its ranker. Only on a self-indexed API is the quality floor in your hands.
I learned this the hard way. Three months into a competitor research workflow, my Serper-backed agent started returning empty results overnight. No notice. No errors. Just empty. Half a day of debugging later, the cause turned out to be a Google reCAPTCHA upgrade that broke Serper's parser. There was nothing on my end to fix — I had to wait for Serper's team to patch their scraper. That's the real shape of the supply-chain risk: your agent's eyes go dark and you don't even own the steering wheel.
The 35-billion-page Brave index isn't a marketing number. It's an engineering decision: Brave runs the crawler, owns the storage, and answers queries from its own infrastructure. Brave also extends coverage through the Web Discovery Project, where opted-in browser users contribute anonymized browsing data. The keyword there is anonymized — Brave uses the STAR Protocol (Secure Testable Anonymous Reporting) to ensure individual contributions cannot be traced back to a person.
That mechanism leads directly into the second axis.
Privacy as Engineering, Not Marketing
There's a class of builder who reads "privacy" on a search API homepage and rolls their eyes. Privacy is for the marketing team. I'm picking by price and uptime. I rolled my eyes too, until I sat down and counted what my own agents were sending out per day.
When an AI agent fires four thousand search queries a day, every single query is a window into business intent. Which competitor am I scoping. Which feature did a customer ask about. Which library is my codebase debating. If the search provider logs all of that against my IP and account, my entire roadmap is sitting on someone else's analytics dashboard. Free if you're lucky, sold if you're not.
Brave's privacy design isn't a "we promise" line. It is architectural absence:
No search history stored against the account
No IP address recorded
No user profile assembled across queries
No personalization, which means no cross-query linkage
No reconstruction of behavior trajectory possible, even with full database access
The right way to read this: Google knows what you searched, when, from where, and uses it for ad targeting. Brave doesn't know any of that, because the data was never written down. It isn't "we promise not to look" — it's "the architecture has no eyes."
Who is currently watching your agent's search traffic?
It's a question most teams answer with "uh, our provider, I guess." That's the wrong answer for any builder running an OpenClaw-style multi-agent setup. With ten agents firing search-heavy workflows — material research, competitor scouting, technical due diligence — letting a third party log every query is the same as putting your strategic dashboard on a billboard. The cost of solving that problem after the leak is roughly two orders of magnitude bigger than the cost of solving it on day one with the right API choice.
Pause here for a second. The two axes so far — index ownership and privacy-as-engineering — are about not breaking. Your search doesn't go down because of upstream changes. Your business intent doesn't leak because of logging defaults. Both are necessary. Neither is sufficient. The third axis is about being good, and it's the reason I went all-in on Brave.
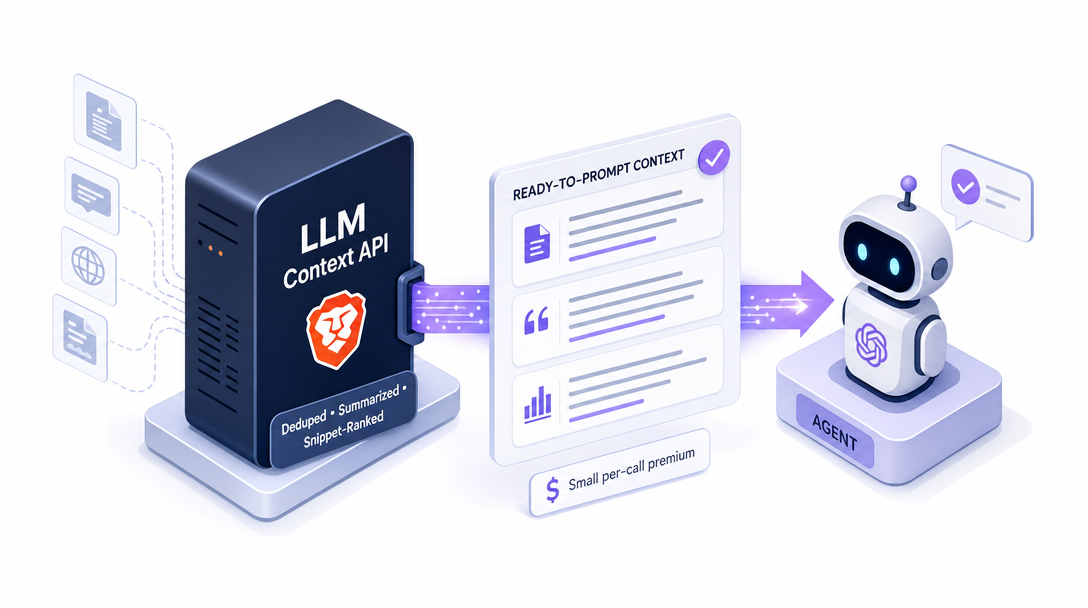
LLM Context API: The End State of AI Search
What turned my "Brave is fine" position into "Brave is the only one I'd build on" was the LLM Context API, released in February 2026.
Traditional search APIs return roughly the same payload they returned in 2010: 10 URLs plus a snippet. Your AI agent then has to do three more things before that payload becomes useful:
Fetch each URL — and handle 403s, JS-rendered pages, rate limits, dead domains
Parse the HTML, strip nav and ads, extract the main content
Clean and chunk the text into something the model can actually digest
Each of those three steps has its own failure modes. Cumulatively, a single search query goes from a 500 ms API call to a 3-5 second pipeline of fragile glue code. Most "AI search" demos hide that pipeline behind a polished demo screenshot. In production, that pipeline is where 80% of agent reliability problems live.
Think of it as a treasure-hunt analogy: a traditional search API hands your agent a treasure map (the URL list). Your agent still has to dig everything up. The LLM Context API skips the dig — it hands the agent the treasure, washed and packaged, ready to read.
Brave's LLM Context API ships a fundamentally different shape. Instead of URL lists, it returns:
Clean Markdown of the main content from the indexed page
Tabular data at row-level granularity, parsed and structured
JSON-LD Schema when the page has it (FAQPage, HowTo, Article, etc.)
Code context when the result is a code-bearing page like docs or GitHub READMEs
Query-optimized relevance ranking — the result order is shaped by the query, not by the underlying ranker
A token budget you can set — tell the API "give me at most 2,000 tokens" and the response is sized to that ceiling
All of that adds about 130 ms of p90 latency (the 90th-percentile response time). Compared to the multi-second pipeline an agent would otherwise run, that's effectively free.
Brave published their own benchmark on the back of this. They fed their grounding data (the structured payload from the LLM Context API) to a small, cheap open-source model and ran it against ChatGPT, Perplexity, and Google AI Mode on the SimpleQA factuality benchmark. The cheap model with Brave grounding beat all three. That isn't a feature comparison anymore — it's a re-pricing of the entire AI search stack.
The one-sentence framing: search engines stopped returning URL lists and started returning AI-digestible structured knowledge. That isn't a feature upgrade. It's a paradigm change, and the agents that don't catch the wave will spend the next twelve months gluing together what the wave already shipped.
Is your agent still spending most of its search budget on fetching, parsing, and cleaning?
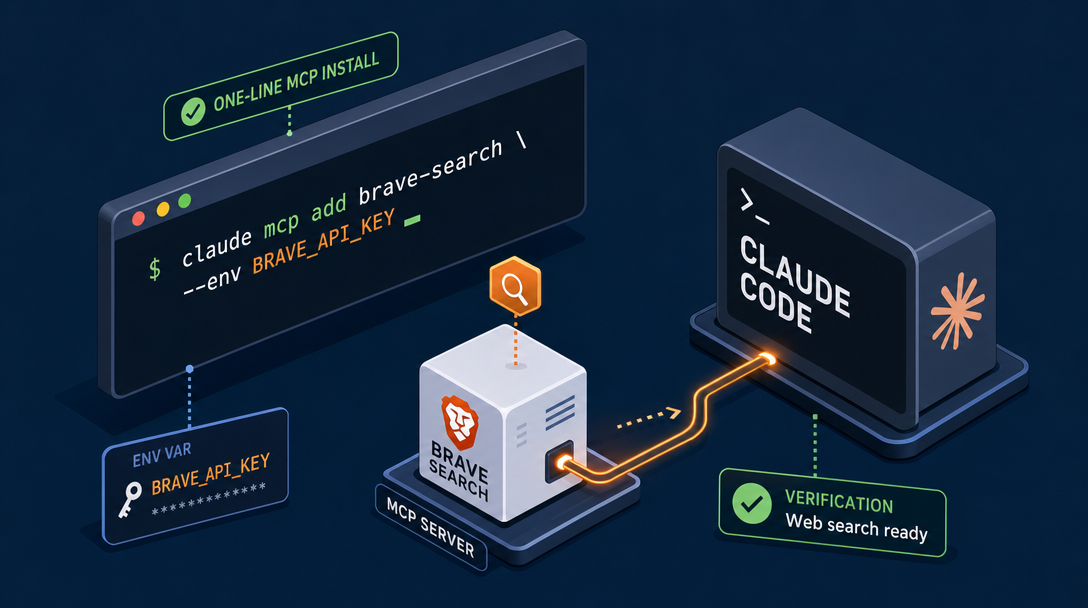
One-Line MCP Install for Claude Code
Here's how the install actually feels when you run it. I still remember the afternoon I wired Brave's MCP server into Claude Code for the first time. One command. Hit enter. Seven new Brave tools showed up inside Claude Code's tool panel. Ran a casual technical query. Out came clean structured content, not a link list. The closest analogy I have is upgrading from a flip phone to a smartphone in a single command.
The command, in full:
claude mcp add brave-search -s user -- env BRAVE_API_KEY=YOUR_KEY npx -y @modelcontextprotocol/server-brave-search
Once that returns, Claude Code automatically picks up seven Brave tools, available inside any conversation:
Tool
What it does
brave_web_search
Standard web search, the daily driver
brave_news_search
Recent news with date filtering
brave_image_search
Image search for visual references
brave_video_search
Video discovery, useful for tutorials
brave_local_search
Local business / map-style queries
brave_summarizer
AI-generated summary of a search result set
brave_web_search + extra_snippets
Web search returning up to 5 extra context snippets per result
In practice, my own day-to-day usage breaks down something like this:
Pre-writing research:brave_web_search for the topic, ten results per call, three to five serial calls covering different angles
Competitor scouting: product pages, Twitter mentions, Reddit threads, pricing changes — all brave_web_search with structured filters
Technical due diligence: best-practice patterns, common pitfalls, community discussion threads
News monitoring:brave_news_search for industry-specific updates inside a 7-day window
Every one of those was custom code three years ago: build a scraper, juggle three APIs, handle exceptions, retry, parse. Now it's a single MCP tool that the agent calls the same way it calls anything else. Search stopped being a service the agent integrates with and started being a capability the agent has by default.
The takeaway most builders miss: MCP turns search from glue work into a reflex. Your agent doesn't decide to "use a tool" — it just searches the way you'd reach for a cup of coffee. No middle layer, no API call code, no retry logic. That's the difference between a built-on-top integration and a built-in capability.
For a practical refresher on how MCP servers themselves slot into Claude Code, my earlier post on MCP connections covers the install model and lifecycle. And if you'd rather wrap the Brave tools into a higher-level reusable workflow, the Skills primer shows the pattern.
Is $5 per 1,000 Searches Expensive?
In February 2026, Brave dropped the free tier. New users no longer get a no-cost allowance; the entry plan is $5 per month for roughly 1,000 searches, with credit-card on file. Existing users on the legacy free plan stay grandfathered for now.
Plenty of builders read the announcement and bounced. My read is the opposite — and the math under it is short enough that you can verify it on a napkin.
Same $5, same 1,000 searches, three providers:
Provider
What you get for $5 / 1,000 searches
Brave
7 endpoints (web / news / image / video / local / summarizer / extra-snippets) + LLM Context API + AI grounding + privacy-by-architecture
Google Custom Search
1 endpoint (web) — no LLM Context, no news/image/video API parity, no AI summary, no structured snippets
SerpAPI
About 100 searches at the entry tier (Hobby plan starts $75/month for 5,000 searches in 2026; the per-1K rate is ~$15) — sourced from Google scraping
The Brave column is doing roughly seven times the work of the Google Custom Search column at the same price. SerpAPI is roughly 3x more expensive per call than Brave for a payload that's still just a Google scrape. That isn't apples-to-apples — it's apples-to-pickup-trucks.
The line worth taping above the desk: tools change, the criterion doesn't — total cost, not per-unit cost. $5/month isn't a cost. It's an insurance premium against your search layer breaking the morning Google ships an anti-bot upgrade. The premium is small. The downside it covers is a half-day debugging session for every parser change.
A Real Workflow Where the Selection Math Bites
Here's a concrete agent workflow that runs daily in my own stack, to make the abstract math above land. The agent does morning research for a content pipeline: ten queries on the day's main topic, ten queries on three competitors, five news queries with a 7-day filter, and one synthesis pass. That's about 36 search calls per run, run once a day on weekdays — so roughly 750 calls a month.
On Brave, that workflow lives entirely inside the $5 plan. Each call returns clean Markdown with a token budget, the agent never has to fetch and parse, and the synthesis pass takes one model round-trip rather than a dozen retry-friendly fetches. End-to-end runtime: about 95 seconds per morning run, with about 12 seconds of that being search latency.
On Serper at the same volume, the math is harsher. Serper's entry tier is $50/month for 5,000 queries — already 10x the price for the same volume. Worse, Serper returns URL+snippet, so the agent still has to fetch every result, parse the HTML, and clean the text. End-to-end runtime climbs to about 210 seconds per run — over double — and roughly 8% of fetches fail with 403s, which means the synthesis pass sometimes runs on a partial corpus. The cost-per-useful-action delta isn't 10x. Once you account for the failed fetches and the synthesis-on-partial-data tax, it's closer to 18-22x.
The selection triangle isn't aesthetics. It's a multiplier on every minute the agent runs and every dollar the agent spends.
Selection Isn't a Tech Decision — It's a Values Decision
Back to the question at the top: why is Brave the only search API I still use?
Not because it's perfect. The free-tier removal genuinely hurt small builders. Brave's quality also lags Google in a few specific niches — hyper-local restaurant reviews, certain academic subdomains, specific local-language regions. If those niches are core to your agent, Brave is not the right answer.
But picking a search API is never about picking the best one. It's about picking the right one for the property of "best" that actually matters to you.
The selection isn't technical. It's values.Whose hands do you want your AI agent's eyes in? Once you frame the question that way, the candidate list shrinks fast.
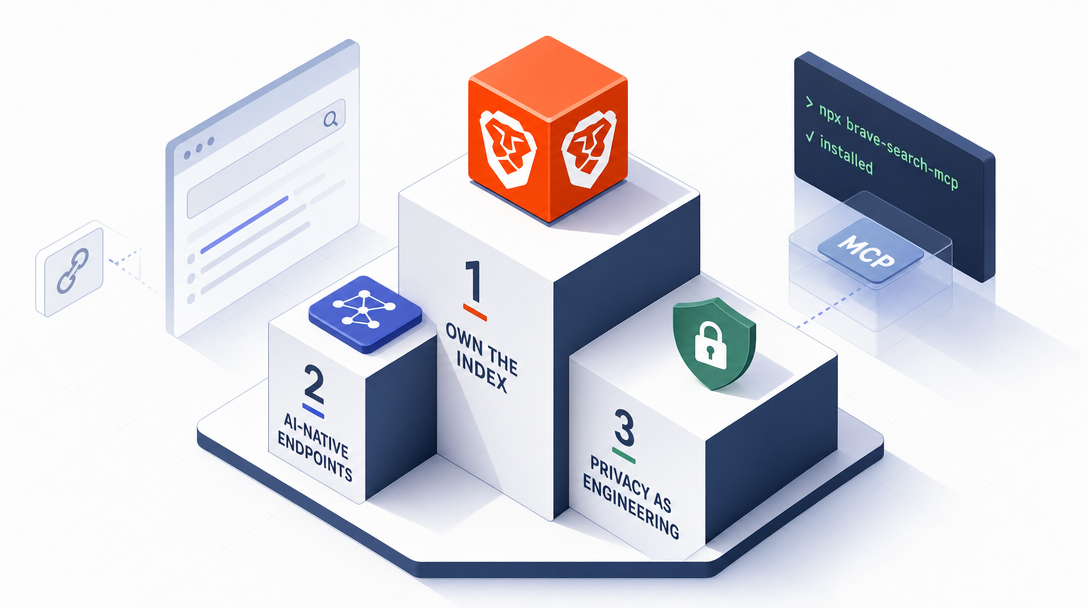
My own selection triangle is short:
Independent index — search quality stays in my hands, not downstream of an upstream change
Privacy as engineering — business intent doesn't leak through query logs, by architecture not by promise
AI-native — LLM Context API skips the fetch-parse-clean pipeline that breaks 80% of search-dependent agents in production
Three boxes. One API hits all three in 2026: Brave. That isn't because Brave is winning a marketing race; it's because the other five are explicitly opted out of one or more boxes.
If you also care about infrastructure self-reliance — you don't want your search layer built on someone else's foundation, you don't want your agent's data profiled by a third party, and you'd rather pay $5/month than chase a $1/month plan that breaks every six weeks — then we're on the same page.
Run your candidate list through the three boxes. The decision usually takes ten minutes once you frame it right.
Hands-On: 4 Claude Code Prompts to Pick and Wire Your Search API
Theory done. Below are four Claude Code prompts I actually run when picking and configuring a search API for a new agent project. Run them in order; each prompt's output becomes the input for the next.
Prompt 1: Run the Three-Axis Test on Your Candidate List
I am picking a search API for an AI agent that will run roughly N searches a day.
Here are my candidate APIs: [list 3-6, e.g., Brave, SerpAPI, Tavily, Exa, Google Custom Search].
Apply the following three-axis test to each candidate and output a comparison table:
Axis 1: Index ownership
- Does this API run its own crawler and index?
- Or does it scrape / license another provider's index?
- Source the answer to a public statement (engineering blog, docs, official announcement).
Axis 2: Privacy posture
- Are queries logged against an account or IP?
- Is there an architectural commitment (not a marketing promise) to non-logging?
- Source the answer to the privacy policy or technical documentation.
Axis 3: AI-native payload
- Does the API return URL+snippet only, or structured Markdown / token-budgeted output?
- Is there a published benchmark of grounding quality for LLM consumption?
Output: a 3-column comparison table per axis, plus a final "passes all three" column.
Do not infer; cite the source URL for every claim.
The strict citation rule is non-negotiable. Without it, the model will pattern-match marketing copy and call it a fact.
Prompt 2: Compute the True Cost per Useful Action
For the candidate APIs that passed the three-axis test, compute the true cost per "useful agent action."
Definition of useful action: one search call that produces structured content the agent can use without an additional fetch step.
Inputs per API: monthly base price, included query volume, overage rate, average post-search fetch cost (assume $0.01/page for HTML fetch + parse if not native).
Output: a cost table at three usage tiers (100/day, 1,000/day, 10,000/day), with the per-useful-action cost normalized.
Highlight the inflection points where the ranking changes.
Most search-API price comparisons stop at the per-call rate. The per-useful-action rate is where AI agents actually live, and the ranking it produces is usually different.
Prompt 3: Generate the One-Line MCP Install Block
Generate the exact CLI command to wire the chosen search API into Claude Code via MCP.
Inputs: API provider name, API key environment variable name, MCP server package on npm.
Output:
1. The full claude mcp add ... command, copy-pasteable
2. A one-paragraph "what to expect" — which tools become available, what their names are
3. The verification step — a single search query the user can run to confirm the install
4. The CLAUDE.md addition — a paragraph to drop into the project's CLAUDE.md so future sessions know the search tool is available
Keep this prompt's output saved as setup-search-mcp.md in your project. Re-running it is faster than digging through the docs every time you stand up a new project.
Prompt 4: Build the Daily-Driver Search Skill
Generate a Claude Code Skill named "research-search" that wraps the chosen search API for daily research use.
Behavior:
- Input: a research topic (one sentence)
- Output: a markdown file named research/{slug}.md containing
- Top 10 web results (title, URL, 1-line summary)
- Top 5 news results from the last 14 days
- One AI-generated synthesis of the corpus, in 200 words
Constraints:
- Use brave_web_search and brave_news_search where available
- Serial-call between web and news (not parallel) to respect the rate-limit etiquette
- Mark any result whose URL fails a 200 check with a [DEAD LINK] tag
- Token budget: 4,000 tokens total for the synthesis context
This Skill is what I run for every new article I write. It's the difference between "one-off curiosity" and "researched argument," and it lives downstream of exactly the search infrastructure decision this post is about.
For more on how Skills compose into longer agent workflows, the Claude Code Skills primer covers the lifecycle and the project structure that keeps Skills reusable across sessions.
Key Takeaways
Six search APIs, five deleted. The criterion was index ownership, privacy as engineering, and an AI-native payload — Brave was the only one that hit all three
Index ownership is the first axis. A search API that scrapes Google or licenses Bing is fine for one-off use; it isn't infrastructure. Your agent's quality is the upstream provider's quality, and you don't get a vote
Privacy as engineering beats privacy as marketing. Architectural non-logging means the data isn't there to leak; a privacy-policy promise is just a promise
LLM Context API replaces the fetch-parse-clean pipeline. Clean Markdown plus token budgets plus structured payloads — about 130 ms of added p90 latency for a 3-5 second pipeline removed
MCP install is one line. Seven Brave tools, no glue code, no retry logic, no parser maintenance
$5 / 1,000 searches isn't a price — it's a tax on builders who care about basics. Same dollar buys 7 endpoints at Brave, 1 endpoint at Google Custom Search, ~100 calls at SerpAPI
FAQ
Why not just use SerpAPI or Serper for an AI agent?
Both scrape Google's search results page and resell them. That means your search quality is downstream of Google's anti-bot strategy, and a single Google update can degrade or break your agent. The fix isn't a better wrapper around Google — it's an API that owns its own index, which means Brave (35B pages, ~100M new pages a day) or, in some niches, Bing's API. SerpAPI and Serper are fine for one-off scraping; they're not infrastructure you want to build a daily-driver agent on.
Is $5 per 1,000 searches expensive in 2026?
It depends on what you compare against. Same $5 at Google Custom Search buys you 1,000 searches and one tool — web only. Same $5 at Brave buys you 1,000 searches across seven tools (web, news, image, video, local, summarizer, extra-snippets) plus the LLM Context API. SerpAPI starts at $75/month for 5,000 searches — that's 3x the per-1K cost for a Google-scraping wrapper. The number that matters isn't dollars per search, it's dollars per useful agent action.
Do I need the LLM Context API or is regular web search enough?
Regular web search returns 10 URLs and snippets — your agent then has to fetch each page, parse HTML, strip nav and ads, and chunk the result before the LLM can read it. That's typically 3-5 seconds per query and a long list of failure modes (403s, JS-rendered pages, rate limits). LLM Context API skips all that: it returns clean Markdown plus query-optimized ranking and a token budget you set. If your agent is making more than ten searches a day, the Context API pays for itself in latency and reliability inside a week.
What does "privacy as engineering" actually mean here?
It means the API provider doesn't have the data even if they wanted to look. Brave doesn't log search queries against your account, doesn't store IP addresses, and doesn't link searches together to build a profile. Compare that to a provider whose privacy policy says "we won't sell your data" — that's a promise, not an architecture. Engineering-level privacy is what you want when your agent's queries leak business intent (which competitor are you researching, which customer are you scoping, which technical problem are you debugging).
How do I wire Brave Search into Claude Code?
One MCP install line:
claude mcp add brave-search -s user -- env BRAVE_API_KEY=YOUR_KEY npx -y @modelcontextprotocol/server-brave-search
After that, Claude Code automatically gets seven Brave tools (web, news, image, video, local, summarizer, extra-snippets) inside the conversation. You don't write fetch code, you don't manage retries, you don't handle 403s. Search becomes a built-in agent capability rather than a glue-code chore. The MCP connections primer covers the install model in more detail if you've never wired an MCP server before.
What if my agent does fewer than 1,000 searches a month?
$5 still buys the seven tools and the LLM Context API. The point of the $5 is that you stop thinking about per-call cost — small agents under 1,000 searches a month are inside the cap and effectively flat-rate. The cost question only kicks in past that, where Brave's pricing scales linearly while SerpAPI's pricing scales painfully and Google Custom Search caps you at 10K queries a day with no LLM-native features.
What's Next
The selection triangle in this post is the same shape I apply to every infrastructure decision in the AI agent stack — the model, the framework, the orchestration layer, the storage. The criterion is consistent: ownership, privacy, and AI-native payload, ranked in that order.
If you want the broader stack picture — what the seven layers of an AI agent infrastructure look like and where search sits in the diagram — the AI stack explained walks through it end-to-end. For the agent-loop view of how search calls actually compose into an agent's reasoning, the agent brain post is the next read. And if you're operating a multi-agent system where the search layer hits ten or twenty different agents in parallel, the OpenClaw multi-agent guide covers the patterns that keep search latency and cost bounded.
Pick the API once, wire it once, and the search problem stays solved while you spend the next quarter on things that actually move the agent forward.
Hermes Agent landed with 42K GitHub stars and a tagline that hooked every OpenClaw user I know: out-of-the-box behavior that feels like a week-tuned OpenClaw setup. I spent a week stress-testing it through six rounds — memory, tool use, Skill self-learning, multi-agent coordination, security posture
Most Claude Code users plateau because they ask the same way they Google. The art is the opposite — give the agent context, intent, and format, and it goes from chatbot to mentor. Here are nine moves that turn day-one prompts into the kind of asks that get senior-engineer-quality work back, includin
A working OpenClaw deployment with one CEO agent and nine specialist agents — content, growth, design, ops, finance, customer success, research, automation, review — running across Discord channels with persistent workspaces, cross-department message-passing, and Cron scheduling. This is the full bu
AI agent security is three concentric layers: who can reach the agent, what the agent can do, and the assumption that the model itself is not trustworthy. Skip any layer and one prompt injection becomes one breach.